web scraper:不用写代码的爬虫插件
最近帮小伙伴下载某学习网站的视频。需要对页面内的数据做一次性的抓取。对于是一次性的抓取需要,能不写代码就不写代码,就用web scraper这个浏览器插件进行链接抓取。
web scraper插件安装
下载链接:https://chrome.google.com/webstore/detail/web-scraper-free-web-scra/jnhgnonknehpejjnehehllkliplmbmhn
需求分析
需求很简单,要抓取两个页面。
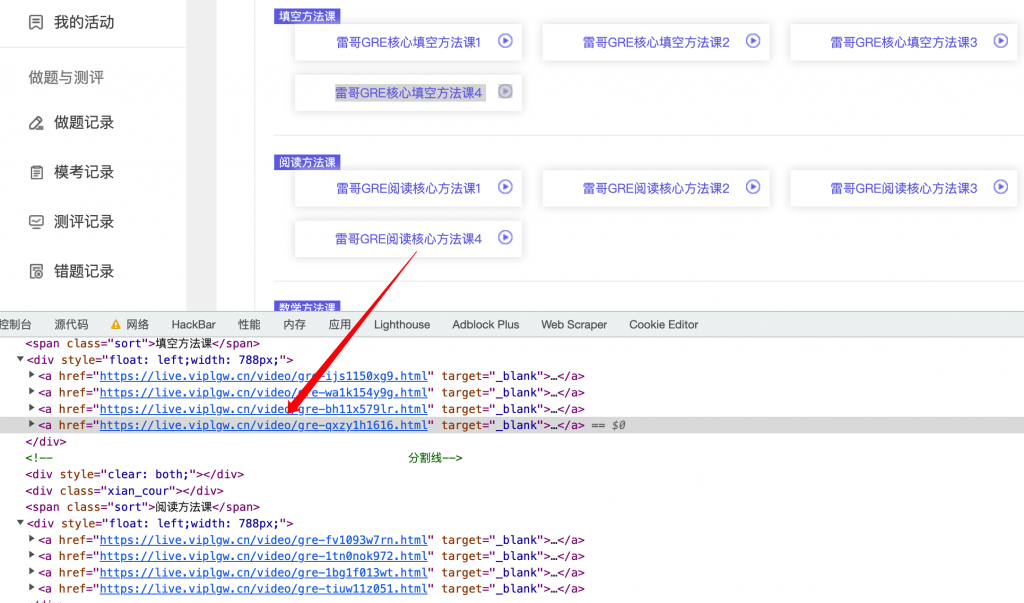
先抓取课程页面中所有视频页面的链接。
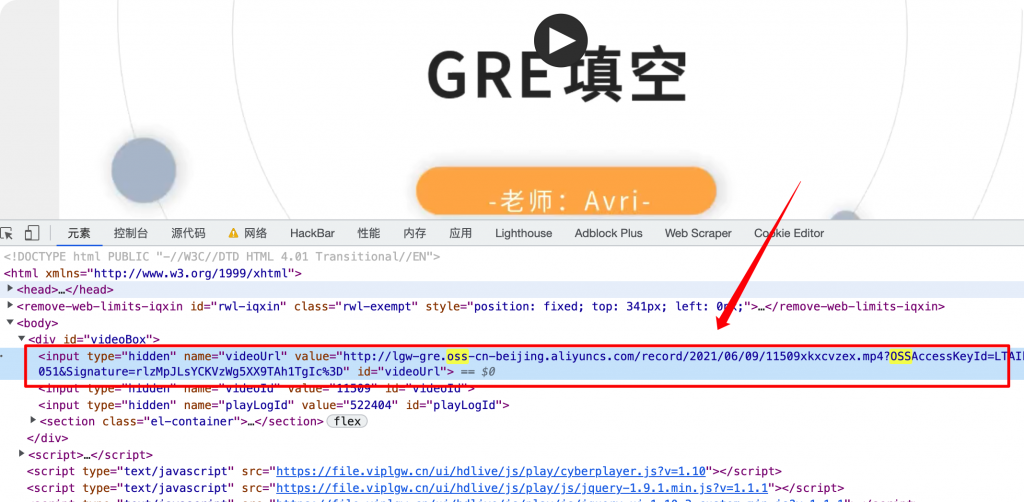
然后在视频页面的中获取视频的真实链接,这里是用的阿里云的oss。
这么简单的抓取,写代码太浪费时间,手动复制又太麻烦。这种场景用插件抓取数据再合适不过了。
web scraper 配置
F12打开控制台,新建一个sitemap。
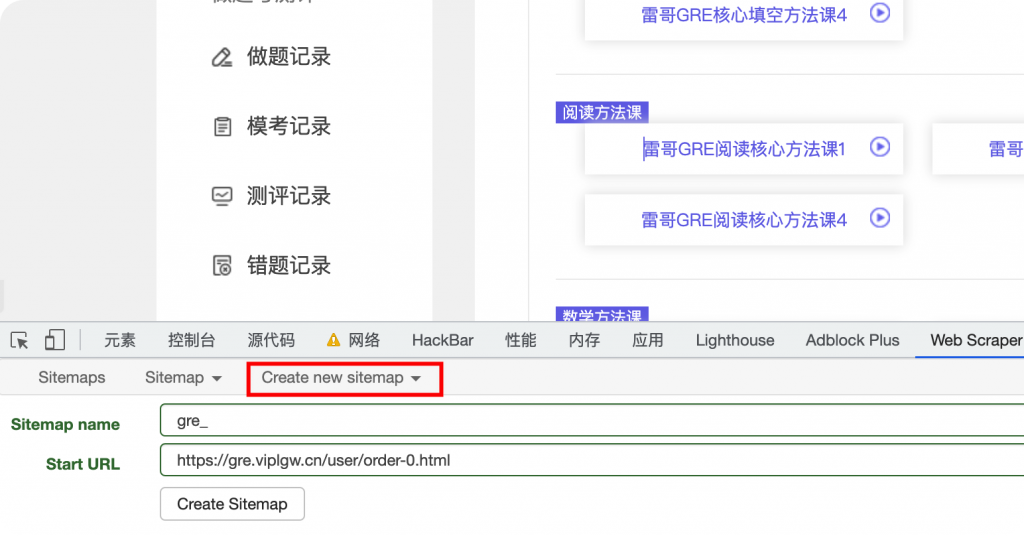
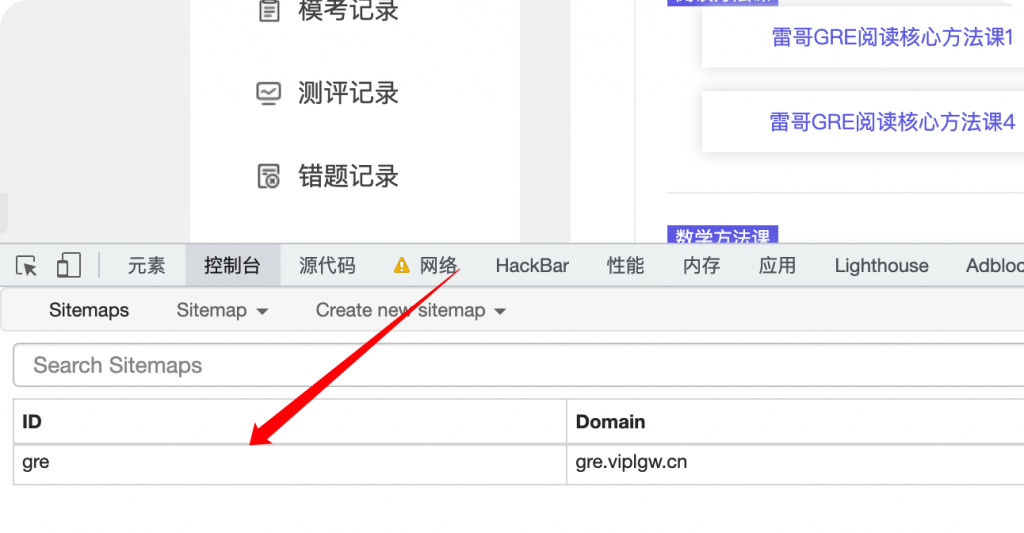
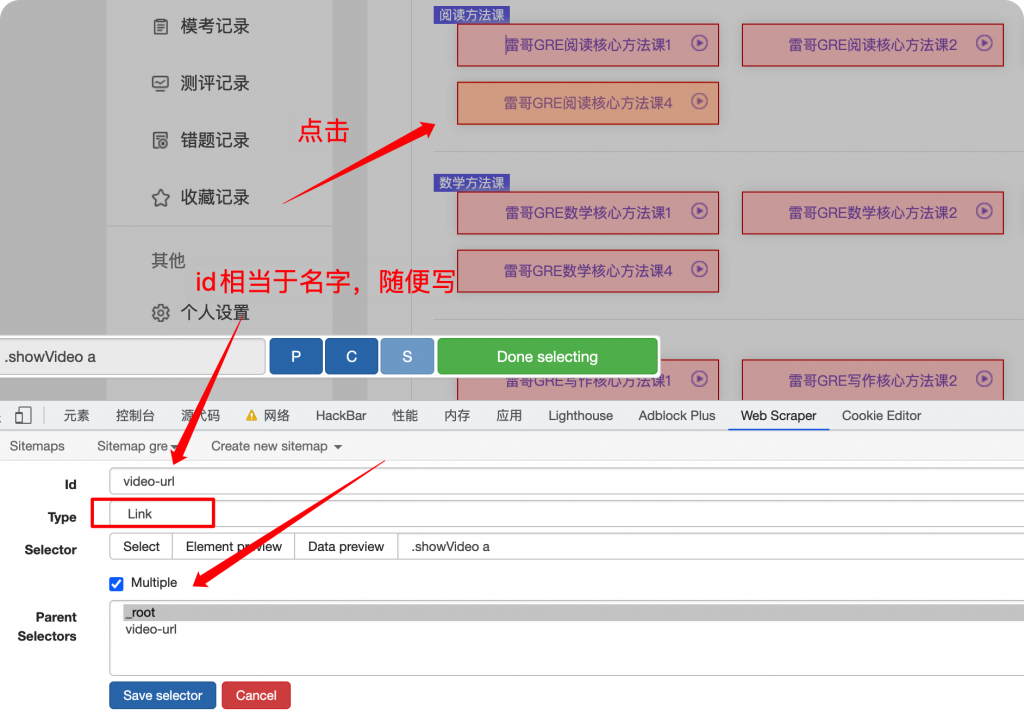
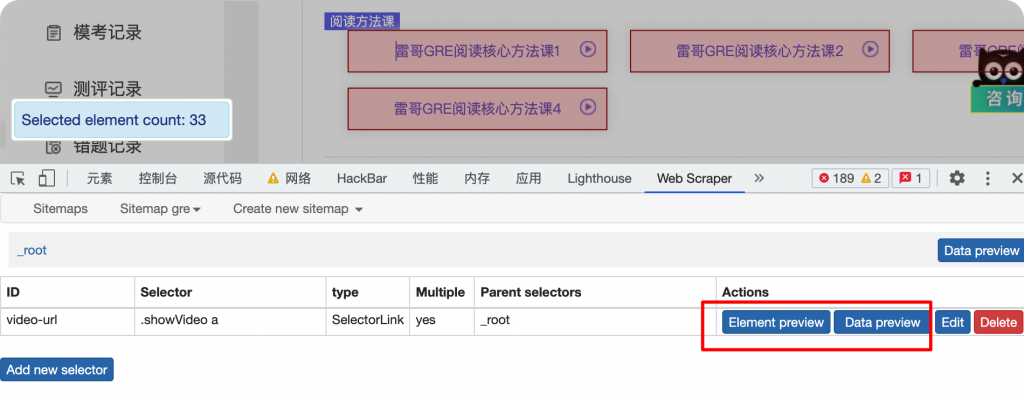
保存后可以预览当前页面被选中的元素。
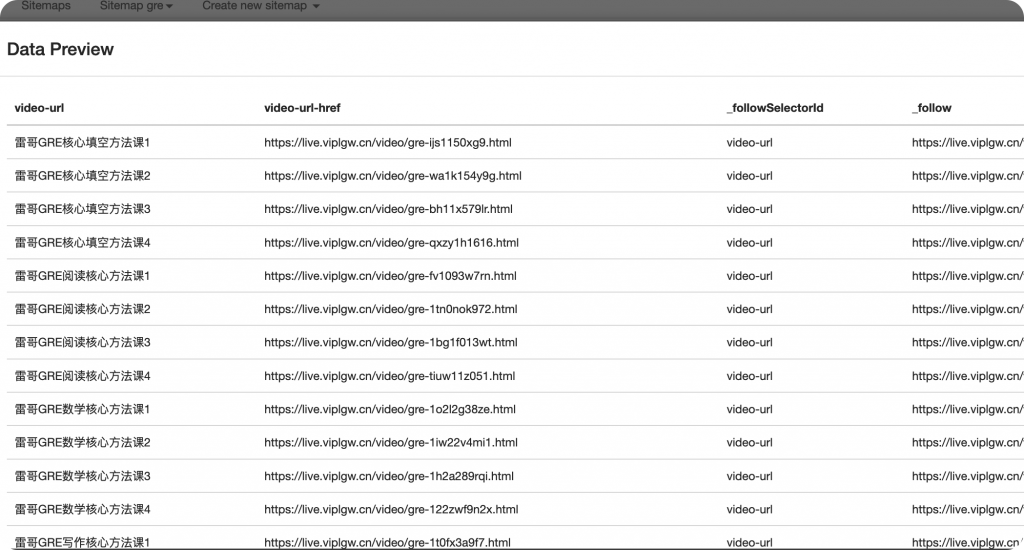
以及预览当前的抓取的链接。
获取到一级页面后,需要通过访问抓取的链接去获取视频url。
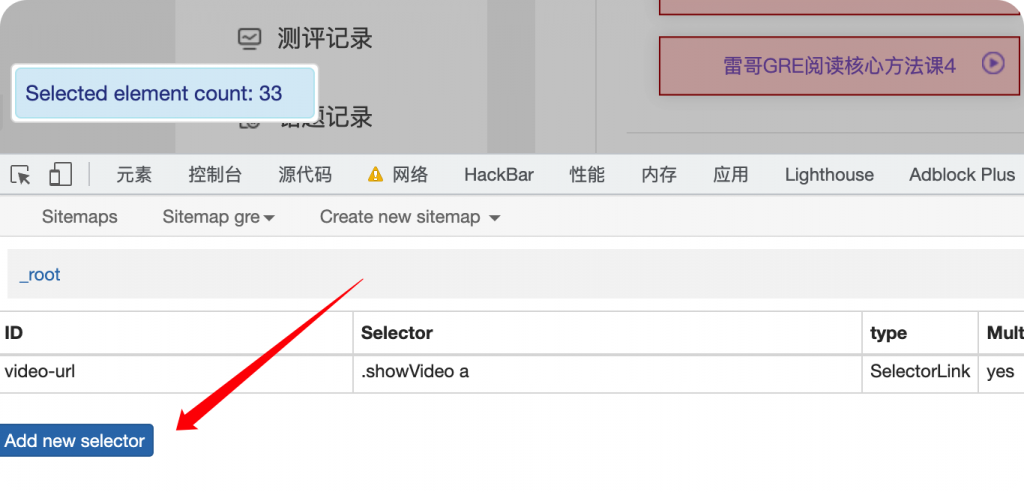
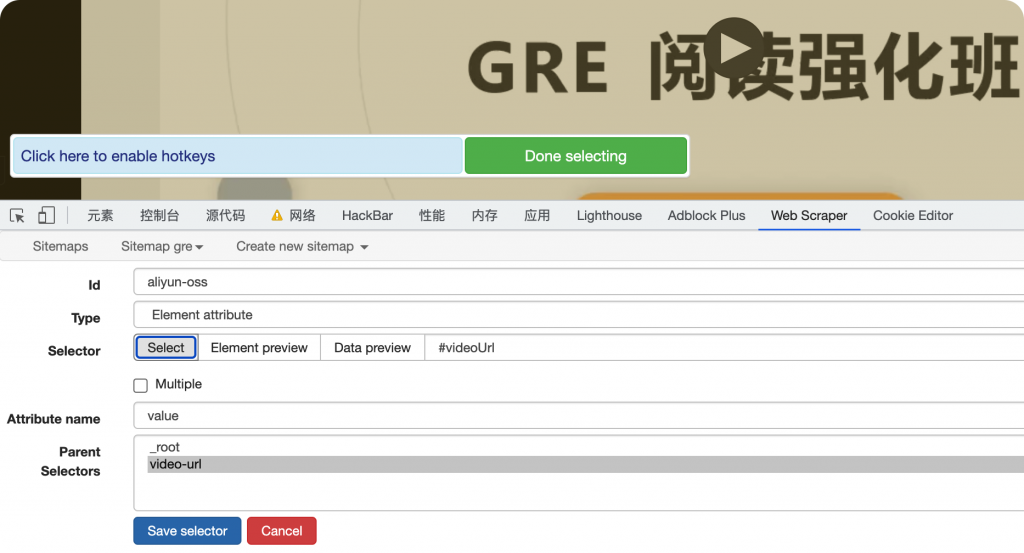
现在来到视频页面,因为input标签是不可见的,所以我们没法像刚才一样通过select去获取元素。
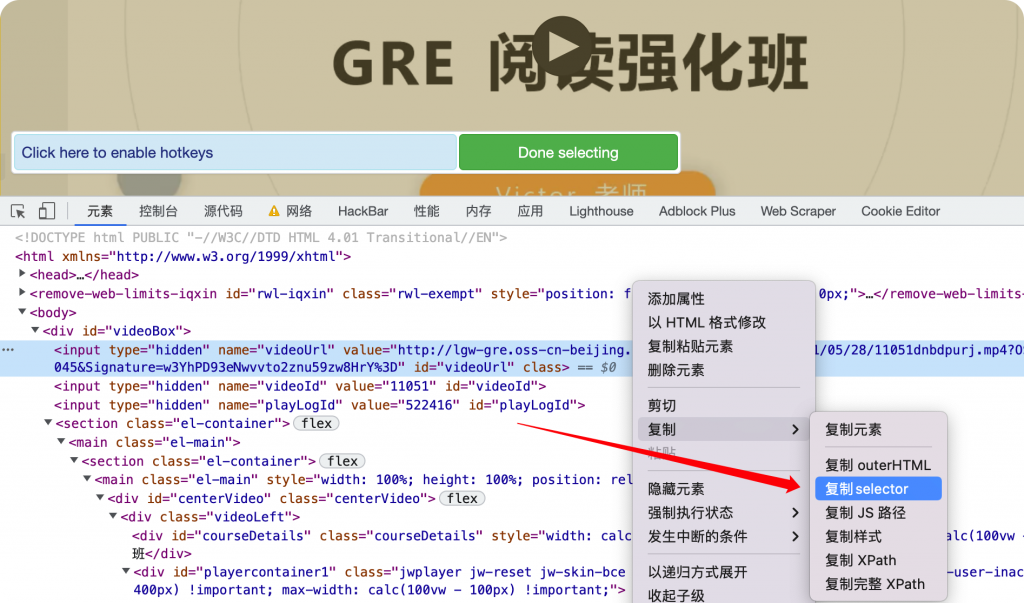
切换到元素tab,右键复制selector。
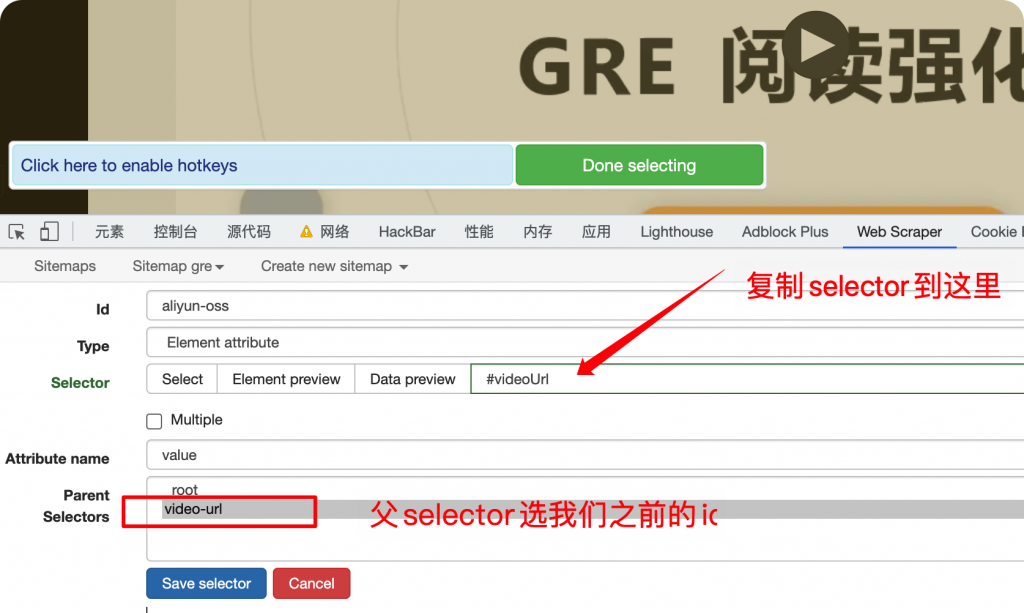
注意抓取的是标签属性,需要选择value。
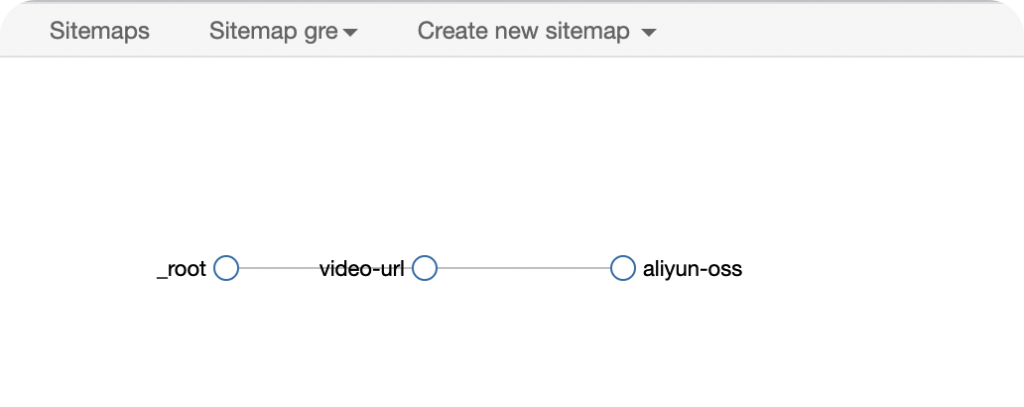
这里可以看到我们爬虫selector的递进关系。
开始抓取数据
遇到阻碍:referer检测

打开第一个页面没有问题,抓取视频页面就会被检测。我搜了下网上的资料,没有解决的办法。
当然web scraper本身还不够强大,不支持自定义header。如果其他人遇到这种情况,估计就算了,不爬了。
但是我仔细想了想,既然web scraper的爬虫本身也是用Chrome进行抓取的,那么其他Chrome的插件也可以生效才对。所以我尝试用 ModHeader 插件手动给他加一个referer头上去。
曲线救国:ModHeader 添加referer头
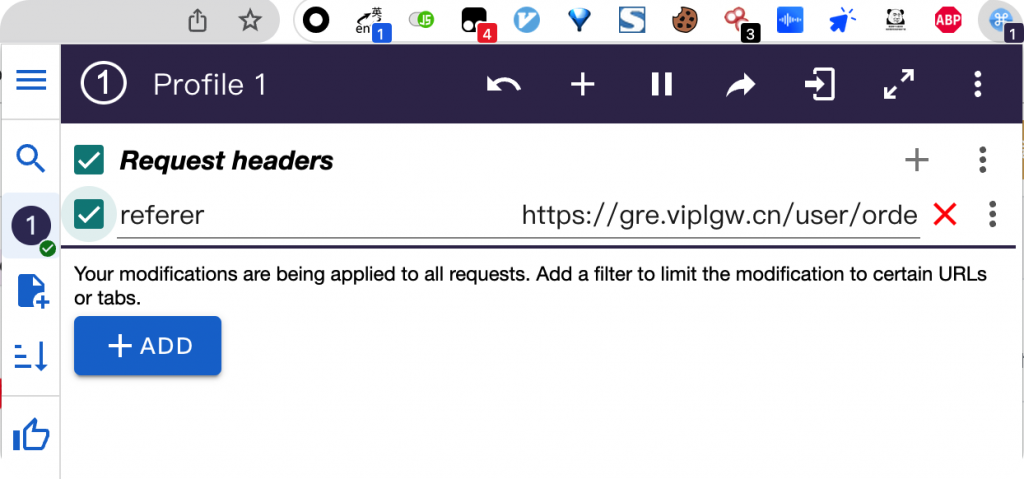
果然奏效!
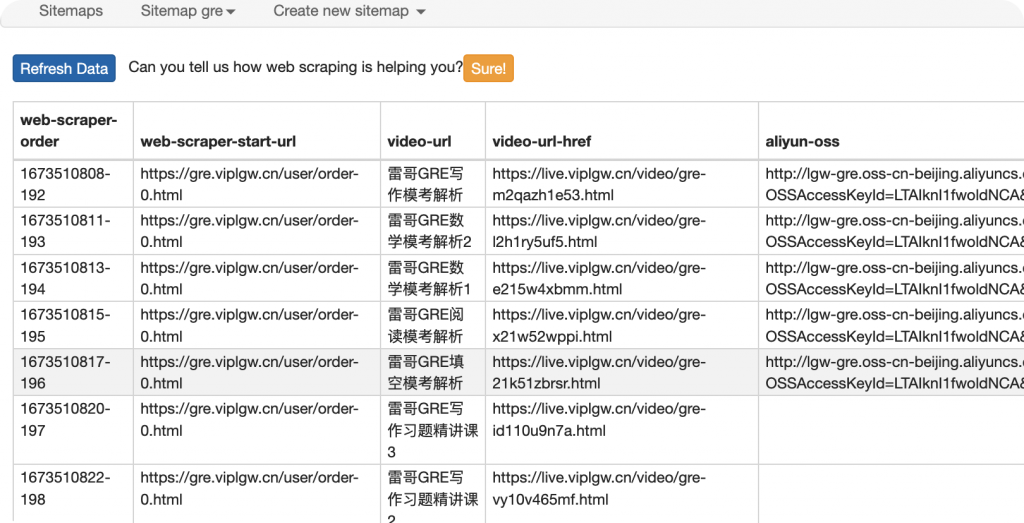
成功抓取到数据。
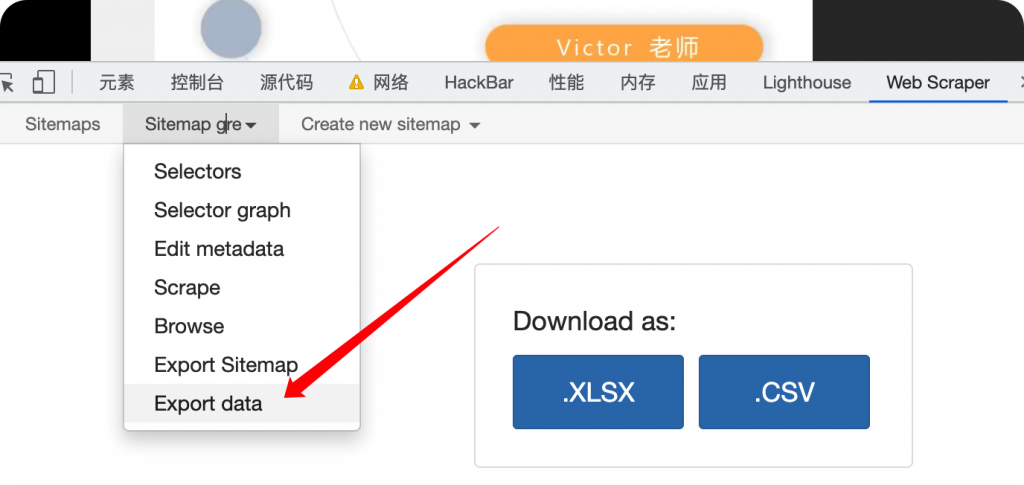
导出即可。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论