Python学习笔记
用于记录自己在python学习中遇到的一些问题以及收获。不定时更新。
python版本号的获取和判断
在某个库中看到判断python版本是否为3的代码。
py3 = sys.version_info.major >= 3
如果为真则py3的值为True。
然后我看了一下sys这个库里的源码。
import sys print(sys.version_info) print(sys.version) --------------------------------- sys.version_info(major=3, minor=6, micro=2, releaselevel='final', serial=0) 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:57:36) [MSC v.1900 64 bit (AMD64)]
所以在判断版本号时就可以这样写
if sys.version_info > (3,6):
print('yes')
else:
print('no')
Requests: Invalid Header Name 解决方法
遇到了这样的报错

关键在于最后一句,意思我相信大家都是能看懂的,但是肯定有人像我一样,没法一下子反应过来。
就像这个错误所说的,我们定义的这个header的accept-encoding并不是一个有效的HTTP header name ,
那么我是怎么定义的呢?如下:
'Accept-Encoding': ' gzip,deflate',
乍一看好像没有什么问题,实际上,我在gzip之前多敲了一个空格,这个就是问题的所在了。
对于Header部分的叙述,总的来说,在header name部分,有诸如空格、冒号之类的,是不被HTTP protocol 标准认可的。
综上,将代码改为:
'Accept-Encoding': 'gzip,deflate',
可解决问题。
pip换源
临时使用:
可以在使用pip的时候加参数-i https://pypi.tuna.tsinghua.edu.cn/simple
例如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gevent,这样就会从清华这边的镜像去安装gevent库。
永久修改,一劳永逸:
linux下,修改 ~/.pip/pip.conf (没有就创建一个), 修改 index-url至tuna,内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
windows下,直接在user目录中创建一个pip目录,如:C:\Users\xx\pip,新建文件pip.ini,内容如下
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
pip一键换源
pip3 config set global.index-url https://pypi.mirrors.ustc.edu.cn/simple/
相比修改文件更加方便。
python判断多个字符串在另一个字符串中
在使用python的开发过程中,常常需要判断,字符串中是否存在子串的问题,但判断一个字符串中是否存在多个字串中的一个时,如if (a or b) in c或者if x contains a|b|c|d…,似乎就需要借助for做循环判断,那么这种情况有没有更pythonic的方法呢?
判断一个字符串中是否存在某一个子串
判断一个字符串中是否存在子串通常使用in关键词,如下:
>>> a = "I Love Crystal!And I Hate Tom!" >>> b = "Crystal" >>> c = "Tom" >>> d = "Jessie" >>> print(b in a) True >>> print(d in a) False >>>
in关键词可以用来判断一个字符串中是否含有一个子串,如"Crystal"在"I Love Crystal!And I Hate Tom!"中,"Jessie"不在"I Love Crystal!And I Hate Tom!"中。
判断一个字符中是否含有多个子串中的一个
问题来了,如果如果我想判断"I Love Crystal!And I Hate Tom!"是否含有"Crystal", "Tom", "Jessie"中的任意一个,只要有其中的任意一个就输出True,应该怎么判断呢?
>>> a = "I Love Crystal!And I Hate Tom!"
>>> name_list = ["Jessie", "Tom", "Crystal"]
>>> for name in name_list:
... if name in a:
... print("got you!")
... break
...
got you!
>>>
我们发现,代码结构看起来还是不够pythonic,有没有更加优雅的写法呢?可以使用内置的any()函数。
>>> a = "I Love Crystal!And I Hate Tom!" >>> name_list = ["Jessie", "Tom", "Crystal"] >>> print(any(name in a for name in name_list)) True >>> name_list = ["Jessie", "Tomi", "Rose"] >>> print(any(name in a for name in name_list)) False >>>
pathlib 和 os.path的区别
pathlib 模块从 python3.4 开始,到 python3.6 已经比较成熟。pathlib是它的替代品,在os.path上的基础上进行了封装,实现了路径的对象化,api更加通俗,操作更便捷,更符编程的思维习惯。对比老式的 os.path,pathblib有几个优势:
1. 传统操作导入模块不统一。 既可以导入 os,又可以导入 os.path,而新的用法统一可以用 pathlib 管理。
2. 传统操作在不同操作系统之间切换麻烦。 换了操作系统常常要改代码,还经常需要进行一些额外操作。
3. 返回的数据类型不同。
- (1)传统主要是函数形式,返回的数据类型通常是字符串。
- (2)但是路径和字符串并不等价,所以在使用 os 操作路径的时候常常还要引入其他类库协助操作。
- (3)Pathlib模块是面向对象,处理起来更灵活方便。
4. pathlib 简化了很多操作,用起来更轻松
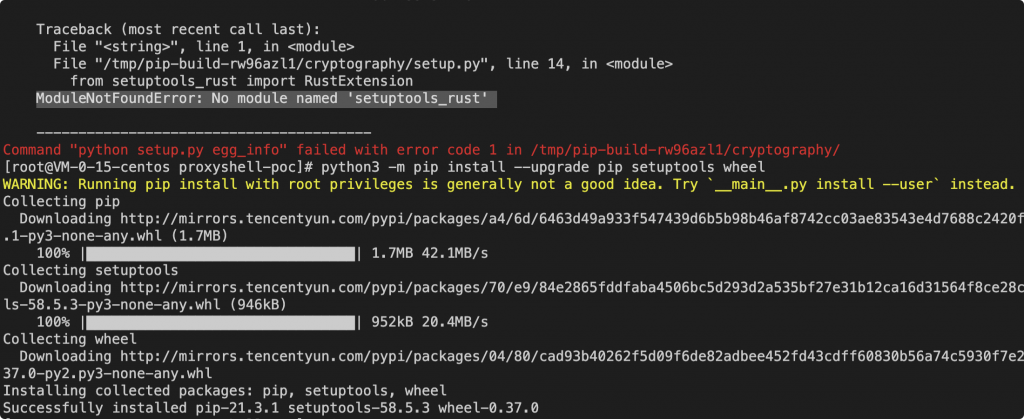
ModuleNotFoundError: No module named ‘setuptools_rust’ 报错
执行下面这个就OK了。
python3 -m pip install --upgrade pip setuptools wheel
python3 socket 中设置超时的几种常用方法
1、默认超时时间设置
socket.setdefaulttimeout(time)
- 参数
time为超时时间,必须放到建立链接的前面,否则超时设置无效果
(这种方式可以设置默认超时时间,包含当前上下文的所有socket连接超时和接收超时有效)
import socket
socket.setdefaulttimeout(5)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
sock.sendall('xxx')
sock.recv(1024)
sock.close()
2、设置某一个socket实例连接或接收的超时时间
settimeout(time) socket实例调用的方法,设置当前socket实例连接或接收的超时时间,参数time为None时恢复默认超时时间
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(5)
sock.connect((host, port))
# 恢复默认超时设置,设置某些情况下socket进入阻塞模式(如makefile)
sock.settimeout(None)
sock.connect((host, port))
sock.sendall('xxx')
sock.recv(1024)
sock.close()
3、使用select来设置超时时间
import select
mysocket.setblocking(0)
ready = select.select([mysocket], [], [], timeout_in_seconds)
if ready[0]:
data = mysocket.recv(4096)
ssl.CertificateError报错处理
解决办法是 :将默认的证书验证模式修改为不需要验证 代码如下
import ssl #将默认的证书验证模式赋值为不需要验证 ssl._create_default_https_context = ssl._create_unverified_context
requests 失败重传
不用自己写, requests 已经帮我们封装好了。(但是代码好像变多了…)
import time
import requests
from requests.adapters import HTTPAdapter
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
print(time.strftime('%Y-%m-%d %H:%M:%S'))
try:
r = s.get('http://www.google.com.hk', timeout=5)
return r.text
except requests.exceptions.RequestException as e:
print(e)
print(time.strftime('%Y-%m-%d %H:%M:%S'))
windows下命令行激活venv虚拟环境
cd venv/Script activate
selenium报错渲染超时解决
driver.save_screenshot(r'./screenshot/' + filename)
用selenium进行截图的时候出现报错:
selenium.common.exceptions.TimeoutException: Message: timeout: Timed out receiving message from renderer:10.0
该报错是因为截图时网站还未加载完成,可以通过停止页面加载的方式解决该报错。示例代码如下:
# !/usr/bin/python3.4
# -*- coding: utf-8 -*-
from selenium.common.exceptions import TimeoutException
from selenium import webdriver
# 打开谷歌浏览器
browser = webdriver.Chrome()
# 设定页面加载限制时间
browser.set_page_load_timeout(10)
# 如果10秒内没有加载完成就会报错
# selenium.common.exceptions.TimeoutException: Message: timeout: Timed out receiving message from renderer: 1.684
try:
browser.get('http://www.amazon.com/dp/B001UPMC1Y')
# 打印html
print(browser.page_source)
except TimeoutException:
# 报错后就强制停止加载
# 这里是js控制
browser.execute_script('window.stop()')
print(browser.page_source)
browser.quit()
pip install 报错error: command ‘gcc’ failed with exit status 1
安装pycrypto的时候出现该报错。
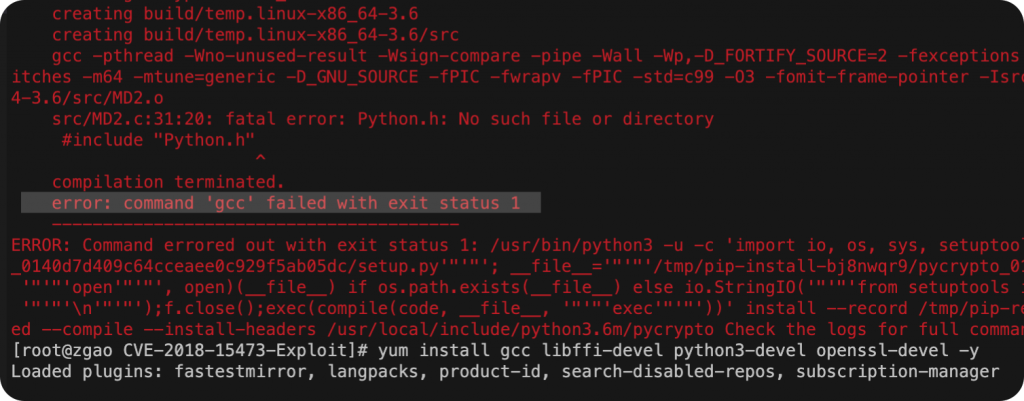
yum install gcc libffi-devel python3-devel python-devel openssl-devel -y
Selenium基于PIL实现拼接滚动截图
from time import sleep
from PIL import Image
import numpy as np
from selenium import webdriver
driver = webdriver.Chrome()
driver.fullscreen_window() # 全屏窗口
driver.get('https://www.qq.com/')
window_height = driver.get_window_size()['height'] # 窗口高度
page_height = driver.execute_script('return document.documentElement.scrollHeight') # 页面高度
driver.save_screenshot('qq.png')
if page_height > window_height:
n = page_height // window_height # 需要滚动的次数
base_mat = np.atleast_2d(Image.open('qq.png')) # 打开截图并转为二维矩阵
for i in range(n):
driver.execute_script(f'document.documentElement.scrollTop={window_height*(i+1)};')
sleep(.5)
driver.save_screenshot(f'qq_{i}.png') # 保存截图
mat = np.atleast_2d(Image.open(f'qq_{i}.png')) # 打开截图并转为二维矩阵
base_mat = np.append(base_mat, mat, axis=0) # 拼接图片的二维矩阵
Image.fromarray(base_mat).save('hao123.png')
driver.quit()
该代码实测可用!
ValueError: set_wakeup_fd only works in main thread报错解决
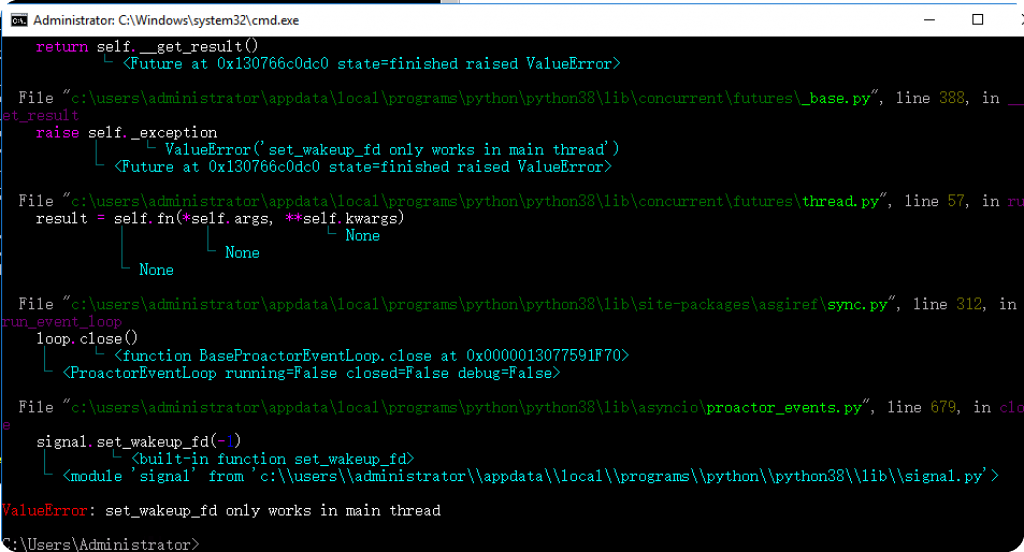
安装的Python 3.8.0 报错,亲测升级到Python 3.9.0就没有问题了。
stackoverflow的回答:
升级到 python 3.8.2 ,在Windows 服务器上运行良好。https://docs.python.org/release/3.8.2/whatsnew/changelog.html#python-3-8-2-final ,问题 bpo-34679:修复了 asynci.ProactorEventLoop.close() 现在仅在主线程中调用 signal.set_wakeup_fd() 。
Centos7通过源码安装python3.10
centos7的yum源默认没有高版本的python。通过源码编译安装 Python 3.10 可以确保你拥有最新版本的 Python 以及对安装选项的完全控制。以下是在 CentOS 7 上从源码编译安装 Python 3.10 的详细步骤:
1. 安装编译依赖
首先,你需要安装编译 Python 所需的依赖。这包括编译器、库和一些工具:
sudo yum groupinstall "Development Tools"
sudo yum install bzip2-devel expat-devel gdbm-devel \
ncurses-devel openssl-devel readline-devel wget \
sqlite-devel tk-devel xz-devel zlib-devel libffi-devel
2. 下载 Python 3.10 源码
访问 Python 官方网站或使用 wget 直接从 Python 官方源下载 Python 3.10 的源码包:
wget https://www.python.org/ftp/python/3.10.0/Python-3.10.0.tar.xz
3. 解压源码包
解压下载的源码包,并进入解压后的目录:
tar xvf Python-3.10.0.tar.xz
cd Python-3.10.0
4. 配置安装
在编译源码之前,你需要配置安装选项。--enable-optimizations 选项会优化 Python,但会使编译过程时间变长。你也可以通过 --prefix 指定安装位置:
./configure --enable-optimizations --prefix=/usr/local
5. 编译和安装
编译并安装 Python:
bash复制代码make altinstall
使用 make altinstall 而不是 make install 可以避免覆盖默认的系统 Python。
6. 验证安装
安装完成后,你可以检查新安装的 Python 版本:
/usr/local/bin/python3.10 --version
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论