pornhub视频地址接口抓取分析&&爬虫源码分享
pornhub这个网站可能大多数人都知道,至于网站什么内容什么的我就不做什么介绍了。如果实在不知道就自行Google吧。当然这是一篇纯粹的技术文章,因为pornhub上的视频是无法直接下载的。通过页面分析pornhub得到视频的源地址,就可以不用挂vpn观看视频或直接下载了。

因为pornhub并没有什么反爬策略,所以分析也比较简单,直接开干。
比如我们在pornhub上搜索考研数学的内容。
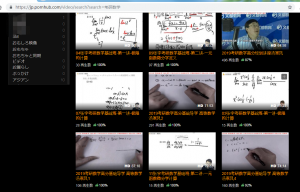
会发现有很多与考研相关的学习视频,但是如何把这些视频给下载来呢。我们随便点击一个学习视频进入相关的页面。
为了分析起来更简便,我就不用抓包工具了。
在该视频页面打开浏览器的开发者工具,再次刷新一下页面。其中第一个加载的资源文件就是该网页的源码。但我们现在需要找到视频加载的地址。为了更快找到,可以把加载的资源列表拖到最下面,然后拉视频的进度条。
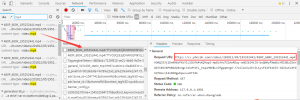
最快的办法是直接搜索mp4关键字,找到相关请求。基本上就成功一半了。我们在右边看到了视频的地址。
此时如果直接打开视频链接打开是什么呢。

由于没有带上URL后面那段参数,所以出现了403的错误。我们再带上参数试试。
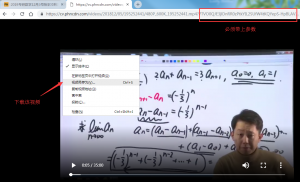
现在就顺利地打开了该视频页面。现在去网页源码中寻找视频的url链接。直接搜索关键字mp4。
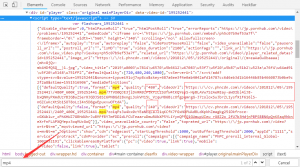
发现是在JavaScript里面的。不过既然在网页中,那么要想提取出来也就很简单了。
原理分析已经清楚了,现在我们用python脚本来自动实现。这里我直接将我写好的代码贴出来。
import re import os import requests print('*' * 50) print(' pornhub视频接口分析抓取工具 -- 无需使用vpn') print(' 欢迎关注我的blog: http://106.15.73.80 ') print(' Author by: zgao') print('*' * 50) print('请输入这种样式的视频url例如:\nhttps://xxxxx.com/view_video.php?viewkey=ph5c07b9ef53a7f') try: os.chdir('pornhub视频接口') except: os.mkdir('pornhub视频接口') os.chdir('pornhub视频接口') while True: url = input('\n请输入pornhub的视频url:').strip() if 'viewkey' not in url: print('传入的url不正确!请重新输入!') continue url = 'http://porn.cdtu.site/view_video.php?viewkey='+url.split('=')[1] try: r = requests.get(url) title = re.search('title.*?title',r.text).group()[6:-7] print('视频标题:',title) url = re.findall('videoUrl":"h.*?phncdn.*?mp4.*?"',r.text) if url[0]: print('抓取视频接口成功!') with open(title+'.txt','w')as f: for i in url: i = i[11:-1].replace('\\','') print(i) f.write(i+'\n') print('该视频接口链接已保存到文件中!\n可在浏览器中直接观看或下载!') except: print('未抓取到该视频接口!')
因为本身分析不难所以代码自然也就简单。我也就不写图形化界面了。
这里我把上面的代码已经打包好了,做成了一个小工具,方便大家使用。
链接: https://pan.baidu.com/s/1wlJLgieOFphewj2WwtlkYA 提取码: 7e42
其中的url抓取就是用正则表达式匹配的,用过用户传入的视频页面地址,向我的网站发起一次get请求。我网站用了nginx反向代理到pornhub,就免去了挂vpn的麻烦。然后根据视频清晰度的不同将url保存的文件中。此时再去打开分析出来的视频url地址就可以直接观看了(不用挂vpn),而且还可以将视频下载到本地。
顺便分享一个我去年写的一个pornhub的爬虫,同样非常简单,仅供参考。
import requests import datetime import pymysql from bs4 import BeautifulSoup db = pymysql.Connect('你的ip', '用户名', '数据库名', '表名') cursor = db.cursor() for page in range(155): page +=1 url = 'https://jp.pornhub.com' url_page = url+'/video?page='+str(page) html = requests.get(url_page) soup = BeautifulSoup(html.text,'lxml') li = soup.find_all('li') for i in li: if i.img and i.button: try: href = url+i.a['href'] title = i.a['title'] var = i.find_all('var') time,looking,release_time= var[0].string,var[1].string,var[2].string Rating_rate = i.find_all('div')[-1].string time_now = str(datetime.datetime.now())[:-7] sql = "insert into pornhub (视频标题,时长,当前观看总量," \ "点赞率,发布时间,视频链接,抓取时间) VALUES ('%s','%s','%s','%s','%s','%s','%s')" \ %(title,time,looking,Rating_rate,release_time,href,time_now) cursor.execute(sql) db.commit() print('视频标题:'+title) print('视频链接:'+href) print('时长:'+time) print('当前观看总量:'+looking) print('点赞率:'+Rating_rate) print('发布时间:'+release_time) print('--------------------------') except Exception: pass print('当前已经爬取到了第'+str(page)+'页!') db.close()
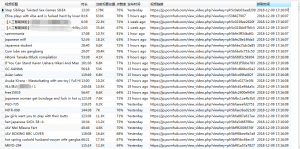
最终在数据库得到的数据就像这样。感兴趣的朋友可以挂上vpn拿这段代码玩一玩。
10月23日更新
由于P站前端页面有所变化,上面的代码已无法使用。请转至我新的一篇博客,链接:
看完Pornhub的视频接口JS混淆后,我顺手写了个下载插件
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
14条评论