Ansible源码分析之find模块
ansible的find模块和linux上find命令非常相似,感觉是find命令的Python代码实现。文档的描述也很简单:根据特定条件返回文件列表。多个条件一起进行“与”运算。对于Windows目标,请改用 ansible.windows.win_find 模块,不过实现上是差不多的。直接分析源码,先看用到的一些模块。
import fnmatch import grp import os import pwd import re import stat import time from ansible.module_utils._text import to_text, to_native from ansible.module_utils.basic import AnsibleModule
- fnmatch 模块主要用于文件名称的匹配,其能力比简单的字符串匹配更强大,但比使用正则表达式相比稍弱。如果在数据处理操作中,只需要使用简单的通配符就能完成文件名的匹配,则使用 fnmatch 模块是不错的选择。
- grp模块,提供了一个Unix 用户组/group(/etc/group)数据库的接口。
- pwd模块,提供了一个Unix 密码数据库(/etc/passwd)的接口,这个数据库包含本地机器用户账户信息。
- stat 模块定义了一些用于解析 os.stat(), os.fstat() 和 os.lstat() (如果它们存在) 输出结果的常量和函数。
再来看一下find模块大概的结构,这几个filter函数的返回都是bool值。
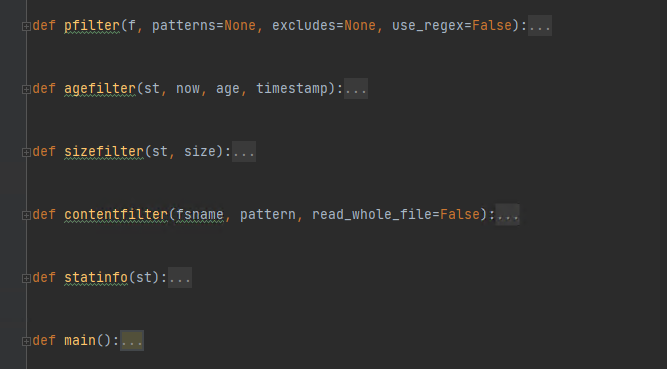
从函数名上面来看,是不是感觉和find命令的参数实现的功能很像。可以根据文件大小,时间,内容等来过滤。先看pfilter的实现。
def pfilter(f, patterns=None, excludes=None, use_regex=False):
if not patterns and not excludes:
return True
if use_regex:
if patterns and not excludes:
for p in patterns:
r = re.compile(p)
if r.match(f):
return True
elif patterns and excludes:
for p in patterns:
r = re.compile(p)
if r.match(f):
for e in excludes:
r = re.compile(e)
if r.match(f):
return False
return True
使用glob模式过滤。从use_regex参数可知,该函数的patterns既可以是正则,也可是普通字符,从而分为了4种情况。而在main函数中可知patterns是一个包含多个pattern的列表。所以对于每个pattern进行match匹配。存在excludes时匹配到了就直接返回False。
else:
if patterns and not excludes:
for p in patterns:
if fnmatch.fnmatch(f, p):
return True
elif patterns and excludes:
for p in patterns:
if fnmatch.fnmatch(f, p):
for e in excludes:
if fnmatch.fnmatch(f, e):
return False
return True
return False
这里就是不使用正则的情况,所以这里匹配就用fnmatch.fnmatch来判断 filename 文件名,是否和指定 pattern 字符串匹配,不过和上面都是类似的。
def agefilter(st, now, age, timestamp):
if age is None:
return True
elif age >= 0 and now - st.__getattribute__("st_%s" % timestamp) >= abs(age):
return True
elif age < 0 and now - st.__getattribute__("st_%s" % timestamp) <= abs(age):
return True
return False
agefilter传入的第一个参数是st,从上下文来看是 st = os.lstat(fsname),而os.lstat返回的是什么呢?
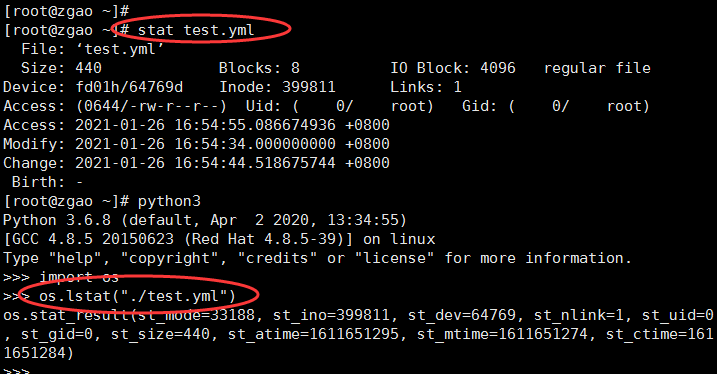
这里我对比了用stat命令和用Python里的os.lstat(),两者获取的信息实际上是一样的。而__getattribute__这个魔法方法的作用又是什么呢?跟进查看
def __getattribute__(self, *args, **kwargs):
""" Return getattr(self, name). """
pass
实际上是用的getattr,也就是反射调用类的其他方法。获取文件的时间戳与传入的age作比较。接下来是sizefilter。
def sizefilter(st, size):
if size is None:
return True
elif size >= 0 and st.st_size >= abs(size):
return True
elif size < 0 and st.st_size <= abs(size):
return True
return False
会发现和agefilter非常相似,只是这里没有用到反射,而是直接获取文件size来比较的。然后是contentfilter。
def contentfilter(fsname, pattern, read_whole_file=False):
if pattern is None:
return True
prog = re.compile(pattern)
try:
with open(fsname) as f:
if read_whole_file:
return bool(prog.search(f.read()))
for line in f:
if prog.match(line):
return True
except Exception:
pass
return False
过滤包含给定表达式的文件,其中参数read_whole_file如果为true,则在对它应用正则表达式之前,将整个文件读入内存。否则,将逐行应用正则表达式。
return bool(prog.search(f.read()))
这里这种写法我觉得是值得学习的,直接用bool来转化结果。如果采用常规写法应该是这样。
if prog.search(f.read()):
return True
return False
显然用bool来返回就简洁很多。
def statinfo(st):
pw_name = ""
gr_name = ""
try: # user data
pw_name = pwd.getpwuid(st.st_uid).pw_name
except Exception:
pass
try: # group data
gr_name = grp.getgrgid(st.st_gid).gr_name
except Exception:
pass
return {
'mode': "%04o" % stat.S_IMODE(st.st_mode),
'isdir': stat.S_ISDIR(st.st_mode),
'ischr': stat.S_ISCHR(st.st_mode),
'isblk': stat.S_ISBLK(st.st_mode),
'isreg': stat.S_ISREG(st.st_mode),
'isfifo': stat.S_ISFIFO(st.st_mode),
'islnk': stat.S_ISLNK(st.st_mode),
'issock': stat.S_ISSOCK(st.st_mode),
'uid': st.st_uid,
'gid': st.st_gid,
'size': st.st_size,
'inode': st.st_ino,
'dev': st.st_dev,
'nlink': st.st_nlink,
'atime': st.st_atime,
'mtime': st.st_mtime,
'ctime': st.st_ctime,
'gr_name': gr_name,
'pw_name': pw_name,
'wusr': bool(st.st_mode & stat.S_IWUSR),
'rusr': bool(st.st_mode & stat.S_IRUSR),
'xusr': bool(st.st_mode & stat.S_IXUSR),
'wgrp': bool(st.st_mode & stat.S_IWGRP),
'rgrp': bool(st.st_mode & stat.S_IRGRP),
'xgrp': bool(st.st_mode & stat.S_IXGRP),
'woth': bool(st.st_mode & stat.S_IWOTH),
'roth': bool(st.st_mode & stat.S_IROTH),
'xoth': bool(st.st_mode & stat.S_IXOTH),
'isuid': bool(st.st_mode & stat.S_ISUID),
'isgid': bool(st.st_mode & stat.S_ISGID),
}
这里试了下pwd和prp获取的信息做了个测试如下,也是上面代码的实现。
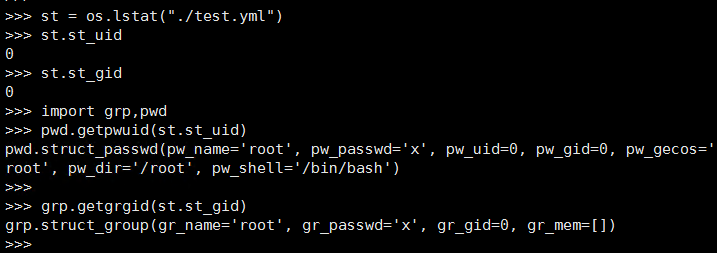
最后返回的字典也就包含了文件所有的信息,不过最值得学习的还是对权限的处理,全部都转换为了bool值,比如
‘wusr’: bool(st.st_mode & stat.S_IWUSR)
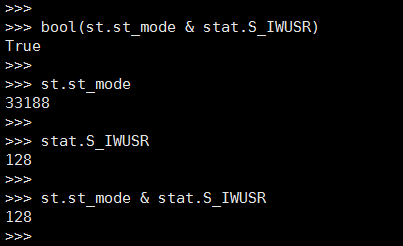
通过按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0。我印象深刻的是之前实习的时候,就在用golang封装各种模块,也就是在造轮子,对应文件权限这一块rwx该怎样去实现弄的我很懵逼,这里转化为bool值或许是不错的方法。
def main():
module = AnsibleModule(
argument_spec=dict(
paths=dict(type='list', required=True, aliases=['name', 'path'], elements='str'),
patterns=dict(type='list', default=['*'], aliases=['pattern'], elements='str'),
excludes=dict(type='list', aliases=['exclude'], elements='str'),
contains=dict(type='str'),
read_whole_file=dict(type='bool', default=False),
file_type=dict(type='str', default="file", choices=['any', 'directory', 'file', 'link']),
age=dict(type='str'),
age_stamp=dict(type='str', default="mtime", choices=['atime', 'ctime', 'mtime']),
size=dict(type='str'),
recurse=dict(type='bool', default=False),
hidden=dict(type='bool', default=False),
follow=dict(type='bool', default=False),
get_checksum=dict(type='bool', default=False),
use_regex=dict(type='bool', default=False),
depth=dict(type='int'),
),
supports_check_mode=True,
)
params = module.params
filelist = []
实例化ansible模块,是每个模块main函数都有的部分,对每个参数的类型的定义。这里没什么好说的。
if params['age'] is None:
age = None
else:
m = re.match(r"^(-?\d+)(s|m|h|d|w)?$", params['age'].lower())
seconds_per_unit = {"s": 1, "m": 60, "h": 3600, "d": 86400, "w": 604800}
if m:
age = int(m.group(1)) * seconds_per_unit.get(m.group(2), 1)
else:
module.fail_json(age=params['age'], msg="failed to process age")
if params['size'] is None:
size = None
else:
m = re.match(r"^(-?\d+)(b|k|m|g|t)?$", params['size'].lower())
bytes_per_unit = {"b": 1, "k": 1024, "m": 1024**2, "g": 1024**3, "t": 1024**4}
if m:
size = int(m.group(1)) * bytes_per_unit.get(m.group(2), 1)
else:
module.fail_json(size=params['size'], msg="failed to process size")
先是判断参数age,转换为小写用正则去匹配。而seconds_per_unit就是每个时间单位对应的秒数,w是表示的一周。正则匹配到了就根据单位转化总秒数。然后判断size参数,都转化为bytes,和age的实现是一样的。
now = time.time()
msg = ''
looked = 0
for npath in params['paths']:
npath = os.path.expanduser(os.path.expandvars(npath))
try:
if not os.path.isdir(npath):
raise Exception("'%s' is not a directory" % to_native(npath))
for root, dirs, files in os.walk(npath, followlinks=params['follow']):
looked = looked + len(files) + len(dirs)
for fsobj in (files + dirs):
fsname = os.path.normpath(os.path.join(root, fsobj))
if params['depth']:
wpath = npath.rstrip(os.path.sep) + os.path.sep
depth = int(fsname.count(os.path.sep)) - int(wpath.count(os.path.sep)) + 1
if depth > params['depth']:
continue
if os.path.basename(fsname).startswith('.') and not params['hidden']:
continue
这段代码中用到了很多的os.path模块的方法,我把用到的列在下面。
- os.path.expanduser(path):把path中包含的”~”和”~user”转换成用户目录
- os.path.expandvars(path):根据环境变量的值替换path中包含的”$name”和”${name}”
- os.path.isdir(path):判断路径是否为目录
- os.path.normpath(path):规范path字符串形式
- os.path.basename(path):返回文件名
- os.path.sep:常量字符串“/”

对传入的路径传入做处理,用到了expanduser和expandvars也就是我们可以用到环境变量里面的值作为参数。looked是记录总共遍历了多少文件和目录的。判断传入的path是否为路径,然后用os.walk来遍历目录,根据depath遍历的深度。如果是文件名前面带点就根据hidden参数判断是否跳过。
wpath = npath.rstrip(os.path.sep) + os.path.sep depth = int(fsname.count(os.path.sep)) - int(wpath.count(os.path.sep)) + 1
乍一看rstrip(os.path.sep) + os.path.sep感觉不对劲,为什么要先去掉”/”,再加上”/”。其实rstrip没有匹配到文本就返回的本身,这里是为了不管路径最后有没有斜杠,最后都添加一个上去。因为通常我们可能会这样写,用切片的方式去判断。
if npath[-1] != "\\":
npath += "\\"
不过还是rstrip(os.path.sep)方式更简洁,学到了!用统计路径中”/”出现的次数来判断深度也是一个不错的方法。
try:
st = os.lstat(fsname)
except (IOError, OSError) as e:
msg += "Skipped entry '%s' due to this access issue: %s\n" % (fsname, to_text(e))
continue
r = {'path': fsname}
if params['file_type'] == 'any':
if pfilter(fsobj, params['patterns'], params['excludes'], params['use_regex']) and agefilter(st, now, age, params['age_stamp']):
r.update(statinfo(st))
if stat.S_ISREG(st.st_mode) and params['get_checksum']:
r['checksum'] = module.sha1(fsname)
filelist.append(r)
elif stat.S_ISDIR(st.st_mode) and params['file_type'] == 'directory':
if pfilter(fsobj, params['patterns'], params['excludes'], params['use_regex']) and agefilter(st, now, age, params['age_stamp']):
r.update(statinfo(st))
filelist.append(r)
用os.lstat获取文件信息,也就是前面提到过的st作为每个函数的参数。因为linux下有7种文件类型。第一种情况是当文件类型是any,且不是目录的时候,调用pfilter和agefilter。
我们前面知道statinfo函数返回的是一个包含文件所有信息的字典,用字典的update将信息合并,并对文件路径取哈希值,而目录是不取哈希的,也就是两个if的区别。从这里可知filelist就是一个 lsit[dict{}]所有文件信息字典的列表。
elif stat.S_ISREG(st.st_mode) and params['file_type'] == 'file':
if pfilter(fsobj, params['patterns'], params['excludes'], params['use_regex']) and \
agefilter(st, now, age, params['age_stamp']) and \
sizefilter(st, size) and contentfilter(fsname, params['contains'], params['read_whole_file']):
r.update(statinfo(st))
if params['get_checksum']:
r['checksum'] = module.sha1(fsname)
filelist.append(r)
elif stat.S_ISLNK(st.st_mode) and params['file_type'] == 'link':
if pfilter(fsobj, params['patterns'], params['excludes'], params['use_regex']) and agefilter(st, now, age, params['age_stamp']):
r.update(statinfo(st))
filelist.append(r)
if not params['recurse']:
break
except Exception as e:
warn = "Skipped '%s' path due to this access issue: %s\n" % (npath, to_text(e))
module.warn(warn)
msg += warn
matched = len(filelist)
module.exit_json(files=filelist, changed=False, msg=msg, matched=matched, examined=looked)
stat.S_ISREG(mode):如果 mode 来自一个常规文件则返回非零值。同时文件类型为file。这里应该是对常规文件的处理,也就多了一个sizefilter函数调用。同样为link链接时是不取哈希的,总的来说都是差不多的。最后还是对错误的一些处理,基本上每个模块相同的部分。
总的来说find模块还是比较简单的,不过学习源码中对文件权限的处理以及过滤匹配,在以后自己造轮子的过程中都是大有裨益的。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论