数据恢复(八)-PDF文件修复实战
上一篇文章中对PDF文件结构进行分析,那么实战中遇到PDF损坏的情况该如何进行手工或工具修复?
案例背景分析
和《数据恢复(六)-SqlSever数据库mdf文件恢复实战》是同样的勒索场景,PDF文件头尾均丢失了256kb的数据。
根据上面的情况分析PDF丢失了哪部分数据?
- PDF文件头
- 文件头后面的部分对象obj
- xref之前的部分对象obj
- 交叉引用表xref
- 文件尾trailer
为什么强调丢失部分对象obj?因为对象obj是PDF的主体部分。
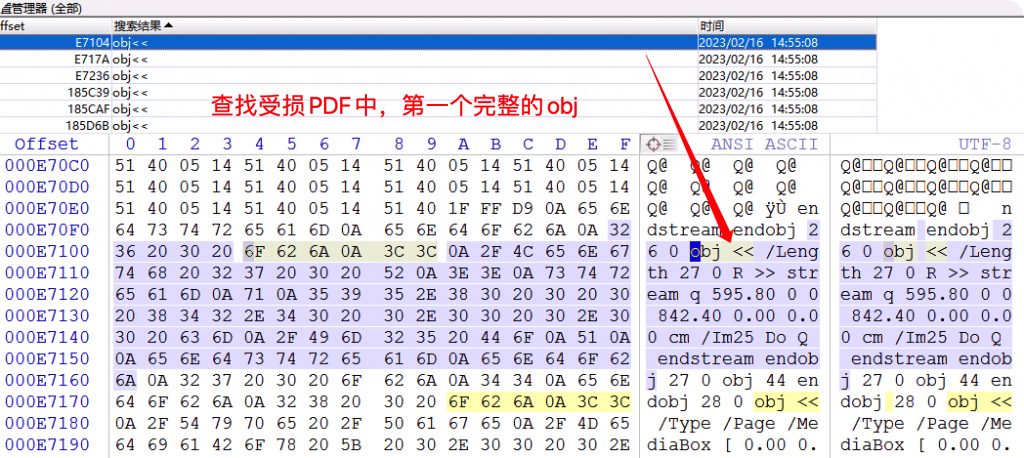
第一个完整的obj编号为26,说明在此之前已经丢失了26个obj对象了(从0开始)。
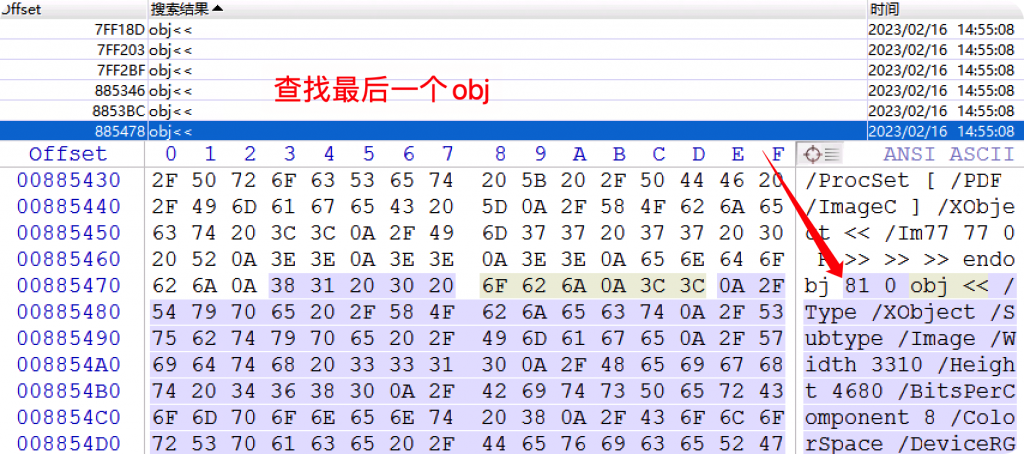
这就意味着,我们最多也就只能恢复pdf文件中的81-26=55个完整的obj。
别担心obj数量太少,没法恢复出来什么数据。比如有的obj是一个图片,数据量占比实则很大。
PDF文件修复思路
按照上面的情况,相当于PDF文件的文件头、xref表、trailer完全丢失。只剩下大部分的obj。
此时只能扫描PDF所有的obj,重新排序计算obj的偏移地址,生成xref交叉引用表和trailer。
PDF修复工具
我对市面上常见的PDF修复工具都进行了测试,发现有三款工具能达到恢复效果。
- 在线修复PDF文件 – iLovePDF
- PDF Recovery Toolbox
- SysInfoTools PDF Repair
这里以PDF Recovery Toolbox工具为例,导入受损的PDF文件。
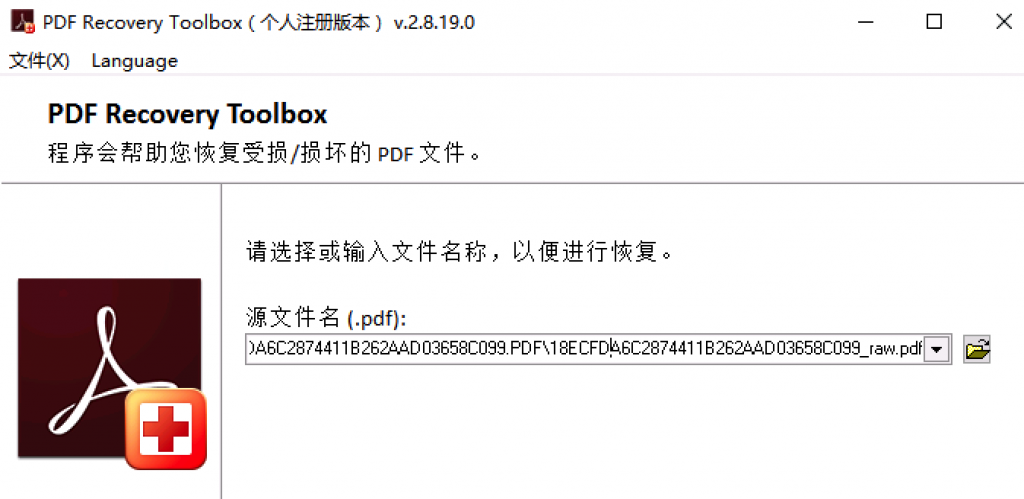
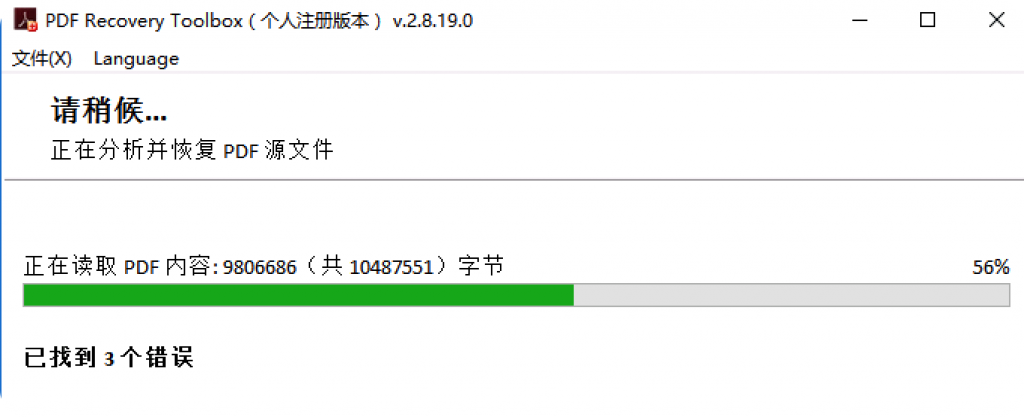
工具会扫描PDF的所有内容重新生成完整的PDF文件。
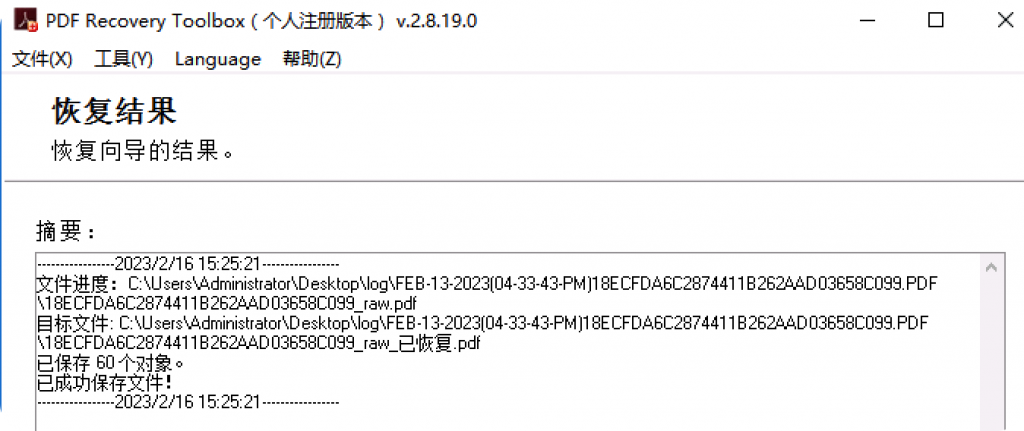
但是工具的缺点是不支持批量PDF损坏文件修复。
PDF手工修复
以图片类型的PDF为例进行分析。
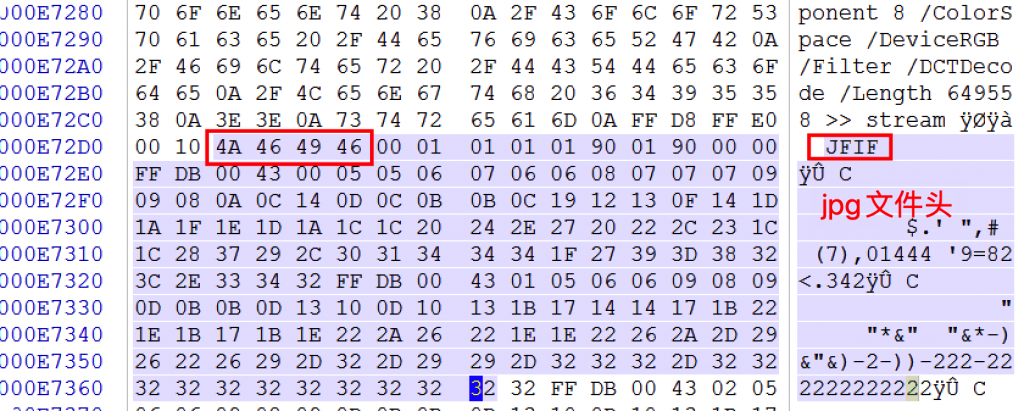
可以通过写代码obj特征提取pdf中的图片内容,这里就不贴代码了,可以自行实现。
foremost提取PDF图片文件
也可以用到foremost。思路很简单,因为PDF文件本身的obj就是嵌入的其他文件,所以其他格式的文件在PDF中还是原样保存的。
apt-get install foremost -y
这里可以把PDF看做一个raw二进制文件,从中提取图片文件。
foremost -t jpg -i damaged_file.pdf -v
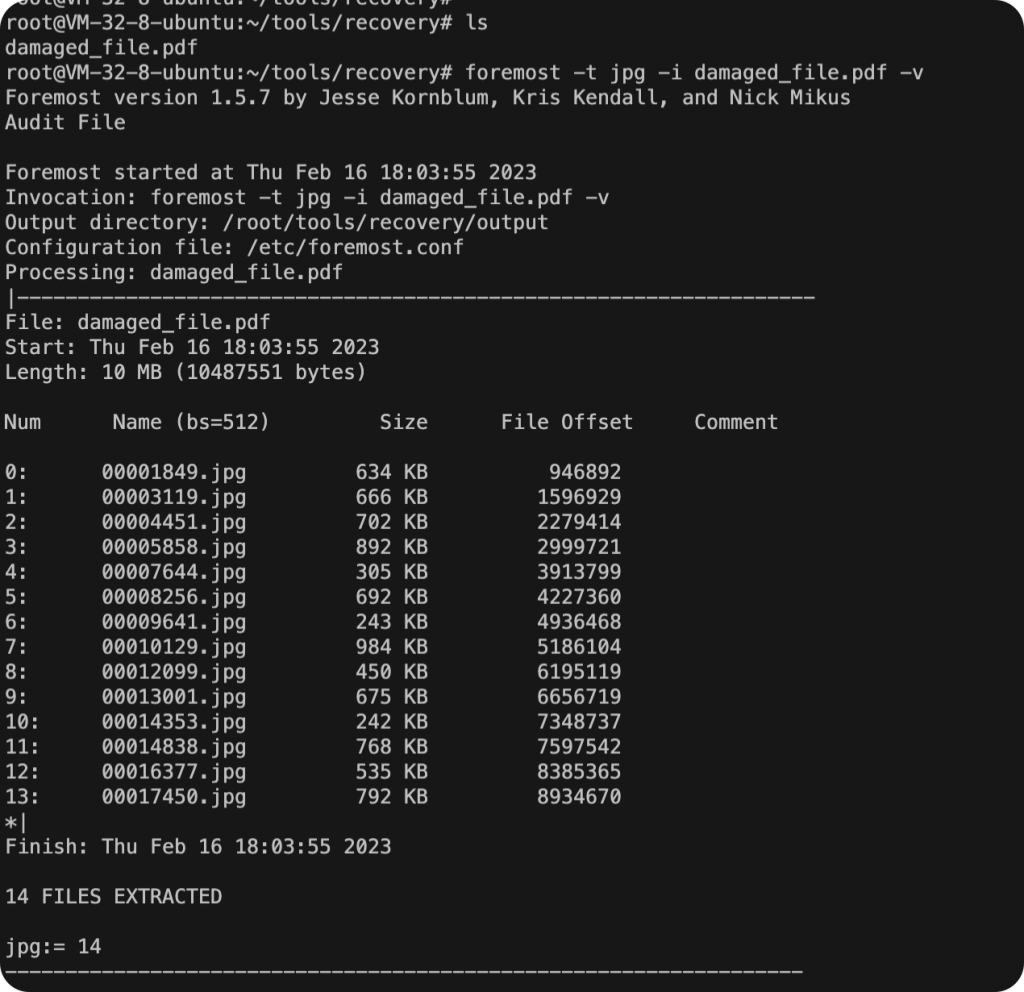
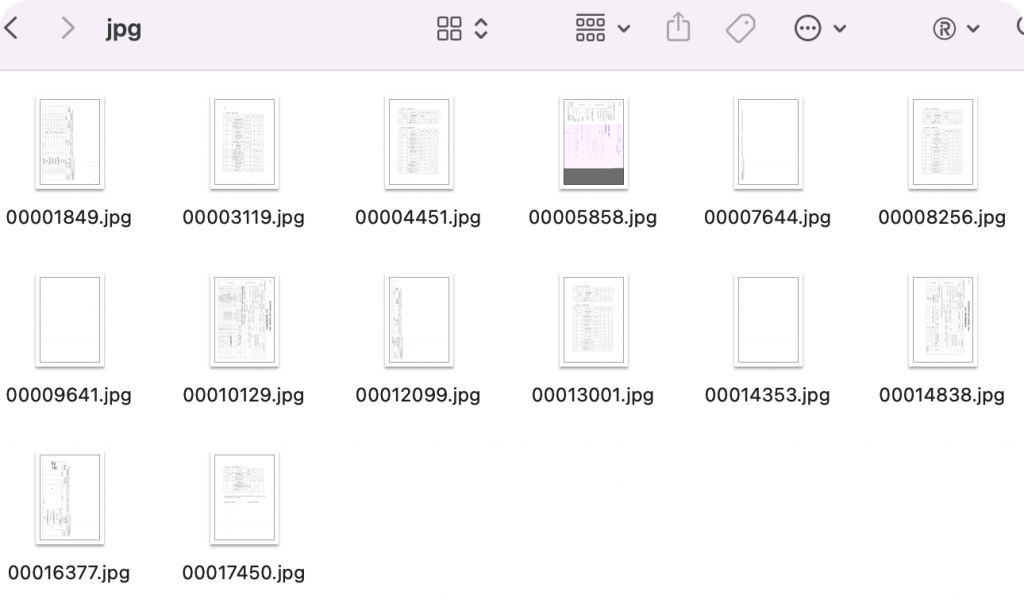
从损坏的pdf文件中提取所有图片文件,再把所有的图片合并到一个新的PDF即可完成修复。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论