用jq解决复杂json的提取
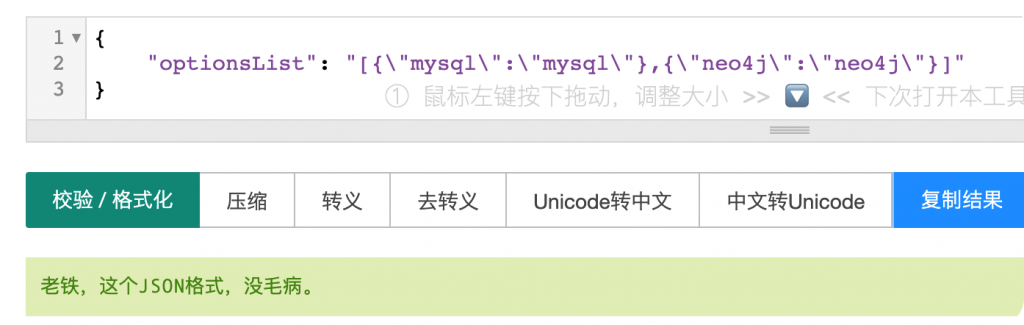
json_str = '''{
"optionsList": "[{\"mysql\":\"mysql\"},{\"neo4j\":\"neo4j\"}]"
}
'''
import json
json.loads(json_str)
# 报错json.decoder.JSONDecodeError: Expecting ',' delimiter: line 2 column 20 (char 21)
这是是一段从浏览器f12提取出来的json,在线json格式校验没有问题,但使用Python的json.loads()加载会报错。
同样使用jq也没有问题。
[root@VM-0-16-centos ~]# echo '''{
"optionsList": "[{\"mysql\":\"mysql\"},{\"neo4j\":\"neo4j\"}]"
}''' | jq
{
"optionsList": "[{\"mysql\":\"mysql\"},{\"neo4j\":\"neo4j\"}]"
}
报错分析
从这段json中,可以看到有使用 \ 反斜杠对双引号进行转义的,推测大概率是转义的问题。
给的JSON字符串中包含了另一个以字符串形式存在的JSON对象。当你尝试使用
json.loads()函数处理该字符串时,Python的解析器将会被内部JSON对象中的转义引号(\")所混淆,从而导致了错误。相较之下,jq能够正确处理这个字符串,因为jq不会试图解析
chatGPT分析optionsList的值为一个内嵌的JSON对象,而只是简单地把它视为一个字符串。
解决思路
import json
json_str_0 = '''{
"optionsList": [{\"mysql\":\"mysql\"},{\"neo4j\":\"neo4j\"}]
}
'''
# 去掉[]外层的引号
dict_obj_0 = json.loads(json_str_0)
json_str_1 = '''
{
"optionsList": "[{\\"mysql\\":\\"mysql\\"},{\\"neo4j\\":\\"neo4j\\"}]"
}
'''
# 对转义的反斜杠再转义
dict_obj_1 = json.loads(json_str_1)
print("dict_obj_0 ->",dict_obj_0["optionsList"][0])
print("dict_obj_1 ->",dict_obj_1["optionsList"][0])
这里我想到两种解决办法,都不会报错。
- 去掉[]外层的引号
- 对转义的反斜杠再转义
运行结果如下:
➜ python3 json_str.py
dict_obj_0 -> {'mysql': 'mysql'}
dict_obj_1 -> [
这里我们都打印第0个对象,都解决了报错。
第一种方案Python把optionsList的value解析成了列表。
第二种方案Python把optionsList的value解析成了字符串。
最优解?
要让Python正确处理json字符串,不管怎么样都得在原本的基础上进行修改替换。试想拿到一个很大的json文件如何正确高效得处理?反正只要能实现需求就对了,用什么方法并不重要。
用jq处理复杂json提取需求
还是用同事给json的做案例,部分json如下。
{
"result": [{
"status": "ON",
"name": "acuxxxvs",
"description": "Acxxxxx扫描",
"displayName": "null",
"version": "1.0.0",
"appxxxst": [{
"status": "ON",
"name": "scannin_task",
"description": "xxxx",
"parameterVariableList": [{
"name": "target_id",
"array": false
}],
"resultxxmptType": "JS",
},
......
}]
}
- 需要提取的字段如下
- 将提取出来的字段转换为表格文件
result name description Version appActionList name description
如果用Python来处理,肯定是for循环提取提取出每个字段后进行拼接,然后写入到csv文件中。
实在过于麻烦,还要解决报错的问题。
jq一条命令就搞定了,命令如下:
cat file.json | jq -r '.result[] | .name + "," + .description + "," + .version + "," + (.appActionList[] | .name + "," + .description)'
用到了jq的管道对多个同一级的字段进行提取,然后统一用 , 进行分隔。
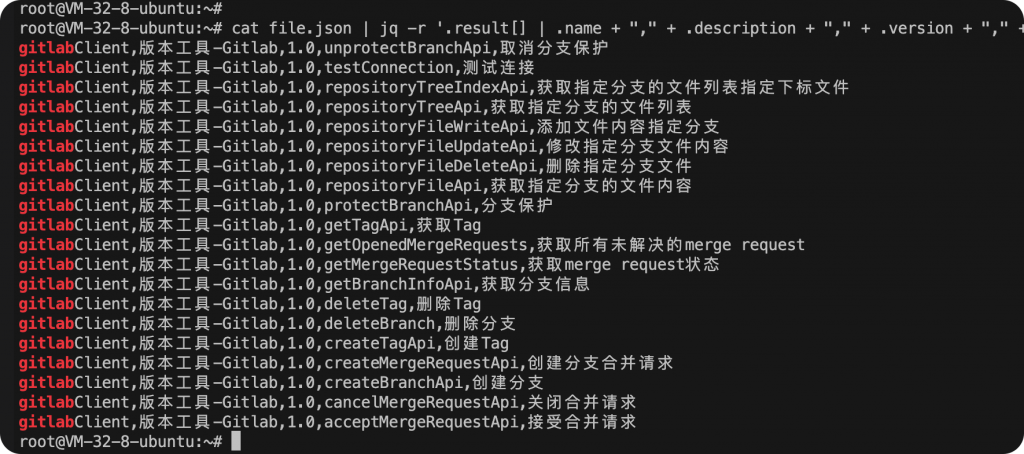
最后把上面的命令结果输出追加到csv文件就搞定了。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
目前为止有一条评论