玩转YY老师服务器(下)之自动化刷题脚本编写
我在上篇文章中已经写过了如何编写IDA的插件来实现伪代码的还原。那我们接下来就可以用Python批量的来完成这件事,也就是实现自动化刷题,用脚本登录yy老师的网站并下载例程,在IDA命令行模式下完成反编译并用上篇文章中写的插件还原C++代码后提交代码,以此完成整个流程。由于我的学号已经无法登录YY老师的网站了,所以我就借我想学习C和C++的理由向YY老师重新要了账号,不过YY老师挺好的,直接就给我了。
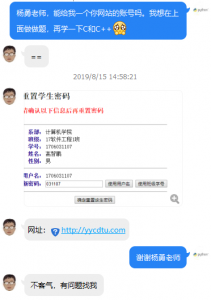
虽然我说在他的网站上做题,可是我又没说我要怎么做。毕竟也没规定代码必须是自己写吧,我用代码来生成代码也没啥问题啊,况且脚本的效率要高得多。不废话,直接分析如何实现吧。
要实现脚本自动化刷题,首先我们肯定要用脚本登录YY老师的网站,那么该如何实现呢。这里我们直接用Chrome的开发者工具分析登录流程。先打开登录页面,输入我们的账号密码登录。
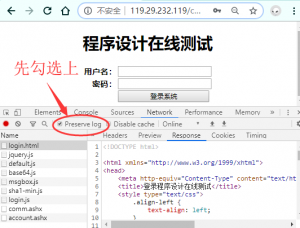
因为登录的时候页面肯定会跳转,跳转前的数据就看不到了,为了能看到完整的数据交互的过程,Preserve log一定要先选上。现在再点击登录。
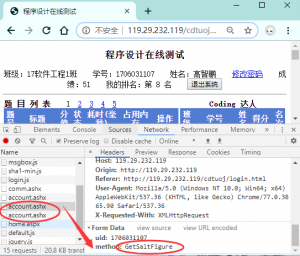
登录成功后直接跳转到了首页,可以看到YY老师写的登录逻辑不是直接post账号密码过去,而是向account.ashx页面发起了两次post请求,第一次是在form表单中post了一个GetSaltFigure。其实就是拿到账号的盐值,所以很容易想到第二个请求才是post密码和盐值加密后的内容过去。现在看第二个请求。
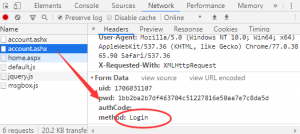
果然如此,那么我们需要分析的就是如何将密码和盐值组合加密的,但不管怎样,加密逻辑肯定是放在js里面。所以我们直接搜索关键字login,果然在YY写的一个login.js的一个login方法里。
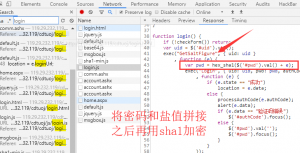
那么我们写脚本的思路也就很清晰了。这里直接放上我脚本的部分代码。
import requests
from hashlib import sha1
def login(uid,pwd):
s = requests.session()
url = 'http://119.29.232.119/cdtuoj/account.ashx'
data = {'uid': uid,'method': 'GetSaltFigure'}
r = s.post(url, data=data)
pwd = pwd + json.loads(r.text)['data']
pwd = sha1(pwd.encode('utf-8')).hexdigest()
data = {'uid': uid,'pwd': pwd,'method': 'Login'}
r = s.post(url, data=data)
if json.loads(r.text)['data']['state'] == '成功':
print('yy老师服务器登录成功!')
return s
else:
print('用户名或密码错误,请检查后重试!')
sys.exit(1)
这样就实现了脚本模拟登录了,最后该函数返回一个session对象给其他函数调用。
那么接下来就是去抓取YY老师网站上页面的题目信息了。为了方便我还是用Beautifulsoup来做的。
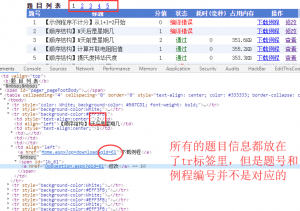
我本来想偷懒直接写个for循环拿到下载例程,但是发现和题号并不对应,所以只好规矩的写爬虫了。不过抓取YY老师这种网站也再简单不过,还是直接放上代码。
def get_info(s):
for i in range(1,6):
data = {'pager_newPageIndex': str(i)}
r = s.post('http://119.29.232.119/cdtuoj/home.aspx', data=data, verify=False)
soup = BeautifulSoup(r.text, 'lxml')
table = soup.find_all('table')[1]
tr = table.find_all('tr')[1:]
for i in tr:
td = i.find_all('td')
num = td[0].string
title = td[1].string
qid = i.a['href'].split('=')[-1]
yield (num,title,qid)
这里用了一个for循环来遍历页数,他只有5页的题,所以就是range(1,6)。另外这次我并没有像往常那样直接把所有的放到列表了,而是直接把get_info写成了一个生成器函数。每次返回一组数据,这样效率也更高了。完成题目信息抓取后,接下来就是下载例程了,同样很简单。
def save_exe(num,title,qid,s):
os.chdir('E:/yy/')
filedir = '第'+num +'题'+ title.replace(' ','')
os.mkdir(filedir)
os.chdir(filedir)
r = s.get('http://119.29.232.119/cdtuoj/Home.aspx?op=download&qid={}'.format(qid))
filename = 'question{}.exe'.format(qid)
with open(filename,'wb')as f:
f.write(r.content)
print(filedir+'的例程下载完成!')
return filename
我是把在E盘下面新建一个名为yy的目录,每道题单独一个文件夹,这样找题的时候也方便,而save_exe接收的参数就是来自于上面yield的返回值。执行上面三个函数即可的下载完所有的例程了。
大概就像这种样子了。既然抓取了所有的例程,下面就是批量的用IDA并结合我们自己写的插件来还原C++代码了。这里我们是脚本运行,自然就不用图形化界面的IDA了,直接调用命令行就好了。也就是IDA的批量模式,网上对此也是有介绍的。
整体说来ida的批量模式并不能算是真正的批量模式,只是可以通过各种手段来执行多个ida进行分析。众所周知ida是不支持多线程的,并且按照官方的说明看来在将来也不准备支持多线程。那么要想进行批量处理就只能使用自己的一些办法,自己去写个程序用命令来调用ida进行处理。
我简单说下如何使用命令行的IDA。我这里用的是IDA 7.0 。以前的版本可能有些不同。
-A让ida自动运行,不需要人工干预。也就是在处理的过程中不会弹出交互窗口,但是如果从来没有使用过ida那么许可协议的窗口无论你是否使用这个参数都将会显示。-c参数会删除所有与参数中指定的文件相关的数据库,并且生成一个新的数据库。-S参数用于指定ida在分析完数据之后执行的idc脚本,该选项和参数之间没有空格,并且搜索目录为ida目录下的idc文件夹。-B参数指定批量模式,等效于-A –c –Sscript.py.在分析完成后会自动生成相关的数据库和asm代码。并且在最后关闭ida,以保存新的数据库。-h显示ida的帮助文档
分别是32和64位的。idat.exe就是我们要用的,因为yy老师的例程代码都是在32位环境下编译的。我们先直接试一下命令行模式。在cmd下运行
C:\Users\Administrator\Desktop\software\IDA_Pro_v7.0_Portable\idat.exe -c -Syy.py E:\yy\第6题【顺序结构】求三角形的面积\question60.exe
先不加-A参数运行,反编译完成后还是停留在了_main函数入口处。此时插件自动运行完成了C++代码的还原。
既然可以通过IDA命令行的方式得到源码了,接下来就是向YY老师的网站提交我们插件生成的代码。先分析一下正常的代码提交流程。我们随便找到题进行提交操作。
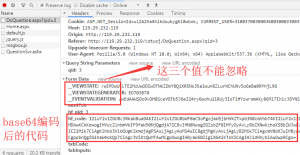
观察form表单很明显,一看hf_code就知道是用的base64编码后传输的。另外上面有三个值有点恶心,一开始我一直以为可省略的无效值,因为以前抓包是也看到过这些字段发现没什么用。结果后面代码一直提交无效才回过头想想应该是这三个值的问题。但是这三个值是隐藏在页面内的,还得自己去抓取,很烦。所以自己还得单独写个函数来做。这个东西大家可以简单了解一下。
aspx网站中form使用到了__VIEWSTATE、__EVENTVALIDATION来验证的提交
__VIEWSTATE
ViewState是ASP.NET中用来保存WEB控件回传时状态值一种机制。在WEB窗体(FORM)的设置为runat=”server”,这个窗体(FORM)会被附加一个隐藏的属性_VIEWSTATE。_VIEWSTATE中存放了所有控件在ViewState中的状态值。
__EVENTVALIDATION只是用来验证事件是否从合法的页面发送,只是一个数字签名,所以一般很短。
“id”属性为“__EVENTVALIDATION”的隐藏字段是ASP.NET 2.0的新增的安全措施。该功能可以阻止由潜在的恶意用户从浏览器端发送的未经授权的请求.

因为他们都是以下划线开头,所以很好提取出来,就不多做解释了,代码如下。
def get_hideinfo(url,s):
d = {}
r = s.get(url)
soup = BeautifulSoup(r.text, 'lxml')
tag = soup.find_all('input')
for i in tag:
if '__' in i['name']:
d[i['name']] = i['value']
return d
这个函数的返回值是一个字典,考虑到post的内容也是字典,所以就把返回值作为参数参数提交代码的函数用update方法合并。
def post_code(s,qid):
url = 'http://119.29.232.119/cdtuoj/DoQuestion.aspx?qid={}'.format(qid)
d = get_hideinfo(url,s)
with open('question{}.cpp'.format(qid),'r')as f:
code = f.read()
code_base64 = str(base64.b64encode(code.encode('utf-8')),'utf-8')
data = {'hf_qid': qid,'hf_code': code_base64}
data.update(d)
r = s.post(url ,data=data,allow_redirects=False)
print('正在提交代码等待中......')
time.sleep(5)
data = {'qid':qid,'method': 'GetStatusForUser'}
r = s.post('http://119.29.232.119/cdtuoj/QuestionSvr.ashx' ,data=data)
state = json.loads(r.text)['data']['state']
print('当前提交代码状态为: '+state)
到这里我门就把代码提交的部分也完成了。虽然所有基本的功能都实现了但是还不够完善,大家也许会注意到我这几段代码都没有做异常处理。其实我是单独写的一个装饰器来实现的。
def get_exception(func):
def new(*args,**kwargs):
try:
return func(*args,**kwargs)
except Exception as e:
print('代码报错已忽略请自行debug,错误信息为:\n',repr(e),traceback.print_exc())
return new
这样代码就变得更加优雅了。下面就是整个完整的自动化刷题脚本代码。
import os
import sys
import json
import time
import base64
import requests
import traceback
from hashlib import sha1
from bs4 import BeautifulSoup
def get_exception(func):
def new(*args,**kwargs):
try:
return func(*args,**kwargs)
except Exception as e:
print('代码报错已忽略请自行debug,错误信息为:\n',repr(e),traceback.print_exc())
return new
def user_input():
uid = input('请输入你的学号信息:').strip()
pwd = input('请输入你的密码:').strip()
return uid,pwd
def check_dir():
path = 'E:/yy/'
if not os.path.exists(path):os.mkdir(path)
os.chdir(path)
@get_exception
def login(uid,pwd):
s = requests.session()
url = 'http://119.29.232.119/cdtuoj/account.ashx'
data = {'uid': uid,'method': 'GetSaltFigure'}
r = s.post(url, data=data)
pwd = pwd + json.loads(r.text)['data']
pwd = sha1(pwd.encode('utf-8')).hexdigest()
data = {'uid': uid,'pwd': pwd,'method': 'Login'}
r = s.post(url, data=data)
if json.loads(r.text)['data']['state'] == '成功':
print('yy老师服务器登录成功!')
return s
else:
print('用户名或密码错误,请检查后重试!')
sys.exit(1)
@get_exception
def get_info(s):
for i in range(1,6):
data = {'pager_newPageIndex': str(i)}
r = s.post('http://119.29.232.119/cdtuoj/home.aspx', data=data, verify=False)
soup = BeautifulSoup(r.text, 'lxml')
table = soup.find_all('table')[1]
tr = table.find_all('tr')[1:]
for i in tr:
td = i.find_all('td')
num = td[0].string
title = td[1].string
qid = i.a['href'].split('=')[-1]
yield (num,title,qid)
@get_exception
def save_exe(num,title,qid,s):
os.chdir('E:/yy/')
filedir = '第'+num +'题'+ title.replace(' ','')
os.mkdir(filedir)
os.chdir(filedir)
r = s.get('http://119.29.232.119/cdtuoj/Home.aspx?op=download&qid={}'.format(qid))
filename = 'question{}.exe'.format(qid)
with open(filename,'wb')as f:
f.write(r.content)
print(filedir+'的例程下载完成!')
return filename
@get_exception
def decompile(filename):
IDA_path = r'C:\Users\Administrator\Desktop\software\IDA_Pro_v7.0_Portable\idat.exe '
args = '-c -A -Syy.py '
cmd = IDA_path + args + filename
os.system(cmd)
print(os.path.basename(filename)+' 已反编译生成为cpp文件!')
def get_hideinfo(url,s):
d = {}
r = s.get(url)
soup = BeautifulSoup(r.text, 'lxml')
tag = soup.find_all('input')
for i in tag:
if '__' in i['name']:
d[i['name']] = i['value']
return d
@get_exception
def post_code(s,qid):
url = 'http://119.29.232.119/cdtuoj/DoQuestion.aspx?qid={}'.format(qid)
d = get_hideinfo(url,s)
with open('question{}.cpp'.format(qid),'r')as f:
code = f.read()
code_base64 = str(base64.b64encode(code.encode('utf-8')),'utf-8')
data = {'hf_qid': qid,'hf_code': code_base64}
data.update(d)
r = s.post(url ,data=data,allow_redirects=False)
print('正在提交代码等待中......')
time.sleep(5)
data = {'qid':qid,'method': 'GetStatusForUser'}
r = s.post('http://119.29.232.119/cdtuoj/QuestionSvr.ashx' ,data=data)
state = json.loads(r.text)['data']['state']
print('当前提交代码状态为: '+state)
if __name__ == '__main__':
check_dir()
info = user_input()
s = login(*info)
for i in get_info(s):
filename = save_exe(*i,s)
decompile(filename)
post_code(s,i[2])
所有代码总共110多行,我完全按照模块化的方式编写的,每个函数的功能结构都十分清晰。下面就用我们写的自动化刷题脚本开干吧。由于pycharm里执行system函数那里会出错,我就直接用Python自带的IDLE演示。坐在一旁开始喝茶,看着脚本脚本自动帮我做题了。
用脚本把YY老师服务器上的题全部刷了一遍,最后我排到了第8名的样子。
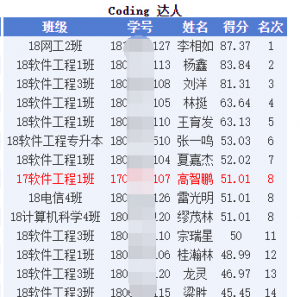
反编译还原的代码并一定都能通过,因为IDA的有些关键字C++编译器并不能处理,脚本的分数还可以更高的,不过这需要再修改一下插件的代码,就目前来看脚本还是挺不错的,混个前10还是没问题的,哈哈。
那么,这也太快乐了吧!
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
4条评论