爬取西刺代理写入Redis数据库自建免费IP代理池
前几天在空间看到同学发说说关于爬取西刺代理遇到了一些问题,所以今天就自己尝试了下。发现爬取页面上的ip本身并不困难,恰好突发奇想既然抓取了这么多免费的代理ip,不如写入数据库来供自己的爬虫使用。所以我就想到了这里用Redis再合适不过了,建立一个自己的ip代理池,美滋滋!

首先看一下西刺代理网站的页面。一眼看上去感觉所有的数据都是放在表格内的。
为了观察更直观,我们直接查看网页源代码。
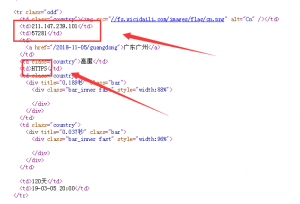
整个网页的结构非常清晰,每一个ip的所有信息都是放在一个tr标签里的。这样几位方便了我们的爬取,直接抓取页面里的每个tr标签里信息即可。
因为抓取数据实在是过于简单,这里我就不多解释,直接上源码。因为本文的主要技术部分不在数据抓取上。而是如何使用Redis数据库建立ip代理池。
import redis
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
redis_pool = redis.ConnectionPool(host='你的ip',password='你的密码')
redis_con = redis.Redis(connection_pool=redis_pool)
def crawl_ip():
key = 0
for i in range(20):
r =requests.get('https://www.xicidaili.com/nn/{}'.format(str(i+1)),headers=headers)
soup = BeautifulSoup(r.text,'lxml')
ip_list = soup.select_one("#ip_list").select("tr")
for i in ip_list[1:]:
info = i.select("td")
ip = info[1].text
url = info[5].text.lower() + '://' + ip + ':' + info[2].text
key +=1
validate_ip(ip,url,key)
def proxies_ip(ip):
if 'https' not in ip:
proxies={'http':ip}
else:
proxies={'https':ip}
return proxies
def validate_ip(ip,url,key):
proxies = proxies_ip(url)
try:
r = requests.get('http://106.15.73.80', headers=headers, proxies=proxies, timeout=1, verify=False)
redis_con.set(key,url)
print('代理ip:{}可用,已存入redis数据库!'.format(ip))
except Exception as e:
print('代理ip:{}不可用!'.format(ip))
if __name__ =='__main__':
crawl_ip()
我先对代码进行解释,其中写了三个函数,我简单画了一个图来帮助大家理解这段代码的结构和原理。
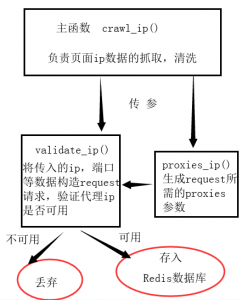
我画图确实有点丑,还请见谅。不过结构非常简单,一看便懂。
这里我主要是想提一下Redis数据库的使用,因为Redis数据库确实是个好东西,因为是用的内存来存取数据所以非常高效。而且上学期我去安天科技面试的时候也被问到过关于redis的问题。所以一直都对redis都情有独钟吧。在之前的文章里也详细介绍过。
Redis 未授权访问漏洞 复现
关于redis数据库的一些基本操作和使用命令,在网上都可以直接找到,我就详细介绍了。比如菜鸟教程上的就写的很详细。
Redis 教程
最后就是给大家看一下这个脚本运行时的截图,还是非常高效的!
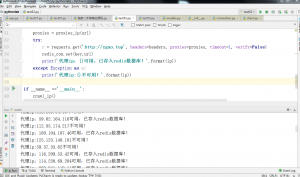
感兴趣的朋友可以自己先建一个redis数据库,然后运行我上面的脚本,就可以实时地抓取免费的代理ip了。我上面写的是抓取20页的数据,大家也可以根据自己的需要自行修改。因为在验证ip可用性的时候会花费一些时间,不过这样也减小了页面请求的并发量。亲测用脚本这样爬几十页的数据是不会被ban的。
如果要爬的ip量确实大,可以考虑用我朋友的办法,以其人之道还治其人之身。把刚提取处理的可用代理ip用作代理继续爬取西刺代理,是不是很棒呢。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
3条评论