一次由于Nginx配置不当导致的内部ddos分析
今早刚一起床,看到昨晚朋友给我发的消息说我们协会的网站挂了,就是那个Google镜像。我打开一看,发现还能正常访问,那现在是没问题的。我看他给我发消息的时间是昨晚12:47。我想的是那个时间段用的人肯定不多,不可能是因为访问量大引起的,为什么挂掉了呢?

所以连上服务器,到nginx的日志目录下查看。
/var/log/nginx/
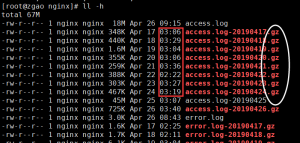
因为时间比较靠前,我直接 head -n 1000 access.log 查看了前1000条日志,发现没有记录??
这里我忽略了两个细节,也是图中标记出来的。
第一个是时间问题,nginx每天都会对前一天的日志进行压缩(我是通过yum安装的),观察时间大概都在凌晨3点左右。我要找当天12点过的日志,应该是在前一天的日志中。
第二个是文件格式的问题,注意结尾是.gz格式的,而不是tar.gz。我犯了一个习惯的错误
上来直接 tar xvf access.log-20190425.gz 然后就报错了。用file命令查看又感觉没错啊。
file access.log-20190425.gz
access.log-20190426.gz: gzip compressed data, from Unix, last modified: Fri Apr 26 03:40:04 2019
这是一个单文件,没有用tar先打包,而是直接用gzip压缩的。正确的解压方式是
gzip -d access.log-20190425.gz
也算是给自己提个醒吧。
正确解压后,因为文件比较大,我就下载到了本地查看,去找到那个时间点。然后。。。。
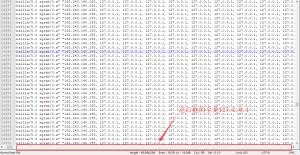
顿时我就傻眼了,这tm是谁干的??
虽然nginx有记录remote_addr,但是都是国外的,难道服务器被攻击了?

我查看了访问ip做了统计,发现除了127.0.0.1的以外的ip都很正常,都是常用的几个ip。也就排除了被攻击的可能性。
awk ‘{print $1}’ 日志地址 | sort | uniq -c | sort -n -k 1 -r | head -n 100
这条命令用于统计Nginx日志文件中ip的出现频率。
为何127.0.0.1会出现高达16000多次,虽然我在Nginx上做了本地反向代理用于端口转发,127.0.0.1出现的频率高是正常的,但是达到这个数字就完全不正常了。
我又去仔细观察日志文件。

我想了一下,那个127.0.0.1不就是记录的x_forwarded_for 吗!!而且一直在递减直到没有,他请求的又是80端口,我似乎感觉到了哪里不对,去看了我的Nginx配置文件。果然问题就出现在这里。
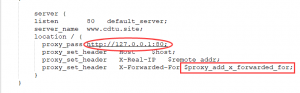
我懵逼了,这不是我自己干的么!!!我不会是个傻子吧??
之前在配置Nginx的时候,虽然我让www.cdtu.site 解析到了80端口,但是我不想让别人从80端口访问到东西,而是80端口监听域名然后转发。所以我就又让他反代到本地80,因为本身80端口没有内容,所以你直接访问80端口的时候就会报错。我以为这样就ok了,当时就没管过他。因为这样会报500的错误,但是不影响其他域名的访问,就没在意。
但是现在想想这也太蠢了,这是一个死循环,访问80端口,他又去访问本地的80,接着又去访问80,不断的循环,会直到资源被耗尽。而变量$proxy_add_x_forwarded_for会去记录代理的ip,这也是为什么日志文件中会有这么多127.0.0.1的原因了。
大家都知道每天互联网上都有大量的扫描,而80端口经常被扫描的。当有大量的外部请求我服务器的80端口,就相当于造成内部ddos攻击,一旦资源被耗尽,Nginx就这样被迫挂掉了。
这次我印象太深刻了。我渐渐明白了那句话的含义了,为什么开发是搬砖的,运维是背锅的了!
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
2条评论