Python标准库源码阅读系列(二)–Re正则模块
本来是打算第二篇写string模块的,但是读完源码后发现很多部分涉及到re模块的内容,就索性先把re模块的源码看了。通读re的源码后发现代码量并不大,很多正则匹配实际是由更底层的sre_compile和sre_parse这两个库来实现的,re模块不过是各种正则方法的封装而已。

下面开始对re源码的阅读分析。
import enum import sre_compile import sre_parse import functools try: import _locale except ImportError: _locale = None __all__ = [ "match", "fullmatch", "search", "sub", "subn", "split", "findall", "finditer", "compile", "purge", "template", "escape", "error", "A", "I", "L", "M", "S", "X", "U", "ASCII", "IGNORECASE", "LOCALE", "MULTILINE", "DOTALL", "VERBOSE", "UNICODE", ] __version__ = "2.2.1"
首先都是对一些必要模块的导入,其中这个_locale库一直没见过,网上也没有太多的介绍资料,直接查看该模块的注释信息发现是Support for POSIX locales(支持POSIX语言环境),也就是当前系统所使用的语言环境。__all__就是所有支持的正则匹配方法以及flags标志。
class RegexFlag(enum.IntFlag): ASCII = sre_compile.SRE_FLAG_ASCII IGNORECASE = sre_compile.SRE_FLAG_IGNORECASE LOCALE = sre_compile.SRE_FLAG_LOCALE UNICODE = sre_compile.SRE_FLAG_UNICODE MULTILINE = sre_compile.SRE_FLAG_MULTILINE DOTALL = sre_compile.SRE_FLAG_DOTALL VERBOSE = sre_compile.SRE_FLAG_VERBOSE A = ASCII I = IGNORECASE L = LOCALE U = UNICODE M = MULTILINE S = DOTALL X = VERBOSE TEMPLATE = sre_compile.SRE_FLAG_TEMPLATE T = TEMPLATE DEBUG = sre_compile.SRE_FLAG_DEBUG globals().update(RegexFlag.__members__) error = sre_compile.error
re模块中只定义了两个类,第一个就是RegexFlag,他是继承的枚举类型。很明显该类是对sre_compile模块中各种标志位的封装,而且进行了简化,平时我们使用正则标志位时,例如re.VERBOSE和re.X就是等价的,用X可代替VERBOSE,更加方便。globals()是一个全局变量字典,通过update方法合并__members__,也就是标志位。不过注意__members__这个魔法方法只是在enum枚举类中定义的,不是通用的。sre_compile.error是一个异常类,继承的Exception类。
def match(pattern, string, flags=0): return _compile(pattern, flags).match(string) def fullmatch(pattern, string, flags=0): return _compile(pattern, flags).fullmatch(string) def search(pattern, string, flags=0): return _compile(pattern, flags).search(string) def sub(pattern, repl, string, count=0, flags=0): return _compile(pattern, flags).sub(repl, string, count) def subn(pattern, repl, string, count=0, flags=0): return _compile(pattern, flags).subn(repl, string, count) def split(pattern, string, maxsplit=0, flags=0): return _compile(pattern, flags).split(string, maxsplit) def findall(pattern, string, flags=0): return _compile(pattern, flags).findall(string) def finditer(pattern, string, flags=0): return _compile(pattern, flags).finditer(string) def compile(pattern, flags=0): return _compile(pattern, flags) def purge(): _cache.clear() _compile_repl.cache_clear() def template(pattern, flags=0): return _compile(pattern, flags|T)
接下来就是re模块封装的各种正则匹配方法。
他们实际是_compile(pattern, flag).对应的方法(string),purge用于清除正则表达式缓存。虽然使用 compile 函数生成的 Pattern 对象的一系列方法跟 re 模块的多数函数是对应的,但在使用上有细微差别。
这里先说一下正则的一般使用步骤(不限于Python语言):
- 使用 compile 函数将正则表达式的字符串形式编译为一个 Pattern 对象
- 通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果(一个 Match 对象)
- 最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
大概就像这样
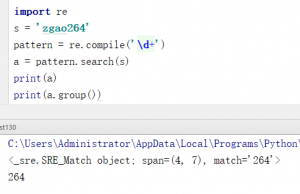
这种方式就像是大多数语言通用的一种正则用法。不过在Python中不一定非得这样写,读了源码后发现常用的正则表达式方法,都已经自带了compile。

所以在Python中使用 re 模块有两种方式:
- 使用 re.compile 函数生成一个 Pattern 对象,然后使用 Pattern 对象的一系列方法对文本进行匹配查找
- 直接使用 re.match, re.search 和 re.findall 等函数直接对文本匹配查找
我也看了一些网上的文章关于Python正则的讨论,也是对于两种方式的争论。
https://wiki.jikexueyuan.com/project/explore-python/Regular-Expressions/re.html
这篇文章的作者认为第一种方式更优,不过我猜作者应该没有通读re模块的源码,后面会分析Python语言对正则的缓存机制。
我们接着看源码。
_alphanum_str = frozenset( "_abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ01234567890") _alphanum_bytes = frozenset( b"_abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ01234567890") def escape(pattern): if isinstance(pattern, str): alphanum = _alphanum_str s = list(pattern) for i, c in enumerate(pattern): if c not in alphanum: if c == "\000": s[i] = "\\000" else: s[i] = "\\" + c return "".join(s) else: alphanum = _alphanum_bytes s = [] esc = ord(b"\\") for c in pattern: if c in alphanum: s.append(c) else: if c == 0: s.extend(b"\\000") else: s.append(esc) s.append(c) return bytes(s)
这里定义了两个字母数字的frozenset(不可变集合),因为Python3 严格区分文本(str)和二进制数据(bytes),文本总是unicode,用str类型,二进制数据则用bytes类型表示。
escape 这个函数就是对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。如果字符串很长且包含很多特殊技字符,而你又不想输入一大堆反斜杠,就可以使用这个函数,非常方便。
 根据代码可知,先判断传入的字符串是str还是bytes型。再把字符串转成列表进行遍历判断字符是否在集合中来转义。但是这里很细节的地方不知道大家是否注意到了。如果是str类型是直接转成列表进行替换,但是bytes类型就先定义一个空列表一次往里面添加,为什么bytes不用替换呢?我们测试一下
根据代码可知,先判断传入的字符串是str还是bytes型。再把字符串转成列表进行遍历判断字符是否在集合中来转义。但是这里很细节的地方不知道大家是否注意到了。如果是str类型是直接转成列表进行替换,但是bytes类型就先定义一个空列表一次往里面添加,为什么bytes不用替换呢?我们测试一下
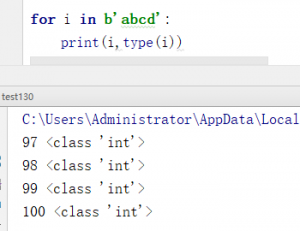
遍历bytes型序列时每个元素都是int型的不能用像字符串一样拼接\\,这也是为什么要先append(esc)再append(c)的原因了。另外s.extend(b”\\000″)这里要用extend而不是append是因为\\000并不是单个ascii码。
接下来就是比较关键的_compile函数了。
_cache = {} _pattern_type = type(sre_compile.compile("", 0)) _MAXCACHE = 512 def _compile(pattern, flags): # internal: compile pattern try: p, loc = _cache[type(pattern), pattern, flags] if loc is None or loc == _locale.setlocale(_locale.LC_CTYPE): return p except KeyError: pass if isinstance(pattern, _pattern_type): if flags: raise ValueError( "cannot process flags argument with a compiled pattern") return pattern if not sre_compile.isstring(pattern): raise TypeError("first argument must be string or compiled pattern") p = sre_compile.compile(pattern, flags) if not (flags & DEBUG): if len(_cache) >= _MAXCACHE: _cache.clear() if p.flags & LOCALE: if not _locale: return p loc = _locale.setlocale(_locale.LC_CTYPE) else: loc = None _cache[type(pattern), pattern, flags] = p, loc return p
首先说一些让我感到疑惑的问题。上面的代码大家可以看到_cache是一个字典,但是这里我纠结了很久。
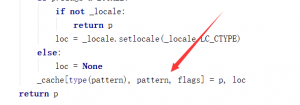
之前一直不知道原来字典还可以这么用。于是打印了_cache的值。
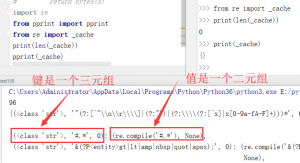
元组也可以作为键key!而且字典默认会将[]中的多个值合并一个元组无需加上括号()。但是测试的时候很奇怪,以文件的形式运行代码(左边),_cache是有缓存的,但是以命令行交互的模式运行却没有(右边)。不清楚是不是IDE的原因,留着以后解决。
为什么元组可以作为字典的键?这引发了我的思考,我做了一个测试。
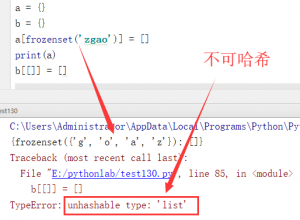
作为字典的键,元组可以冻结的集合(不是普通集合,不可修改)也行,因为他们都有一个共同的特点就是不可变!但是这个就得从字典的性质说起了,就不在这里讨论了。
疑惑解决了,接着看代码。_MAXCACHE是定义的一个最大缓存。同一个正则表达式,同一个flag,那么调用两次_compile时,第二次会直接读取缓存。但是当缓存大于512时就会清理缓存。所以上面那位老哥的说法就不对了。传入正则的时候,Python会先查找缓存,如果没有再编译,也不存在什么效率大打折扣。
同时我在知乎上看到了另外一位的老哥的文章,大家可以点击看一下
Python正则表达式,请不要再用re.compile了!!!
虽然这位老哥说的没错,但是我觉得他这种观点还是言之过激。Python语言本身提供了这两种机制使用正则,只是后者写起来更简便更pythonic,对于这两种方式我觉得没必要过于争论孰优孰劣。
@functools.lru_cache(_MAXCACHE) def _compile_repl(repl, pattern): return sre_parse.parse_template(repl, pattern) def _expand(pattern, match, template): template = sre_parse.parse_template(template, pattern) return sre_parse.expand_template(template, match) def _subx(pattern, template): template = _compile_repl(template, pattern) if not template[0] and len(template[1]) == 1: return template[1][0] def filter(match, template=template): return sre_parse.expand_template(template, match) return filter
这里用到了functools.lru_cache装饰器。functools.lru_cache的作用主要是用来做缓存,他能把相对耗时的函数结果进行保存,避免传入相同的参数重复计算。同时,缓存并不会无限增长,不用的缓存会被释放。不过这几个都是内置函数,供其他函数使用的,就不必深究。
import copyreg def _pickle(p): return _compile, (p.pattern, p.flags) copyreg.pickle(_pattern_type, _pickle, _compile)
copyreg 模块提供了可在封存特定对象时使用的一种定义函数方式。用 copyreg 实现可靠的 pickle 操作,大家都知道pickle模块是用于对相关对象执行序列化和反序列化操作。如果用法比较复杂,那么 pickle 模块的功能也许就会出问题。可以把内置的 copyreg 模块同 pickle 结合起来使用,以便为旧数据添加缺失的属性值、进行类的版本管理等。这里注释也写了,就是自我注册。
class Scanner: def __init__(self, lexicon, flags=0): from sre_constants import BRANCH, SUBPATTERN if isinstance(flags, RegexFlag): flags = flags.value self.lexicon = lexicon p = [] s = sre_parse.Pattern() s.flags = flags for phrase, action in lexicon: gid = s.opengroup() p.append(sre_parse.SubPattern(s, [ (SUBPATTERN, (gid, 0, 0, sre_parse.parse(phrase, flags))), ])) s.closegroup(gid, p[-1]) p = sre_parse.SubPattern(s, [(BRANCH, (None, p))]) self.scanner = sre_compile.compile(p) def scan(self, string): result = [] append = result.append match = self.scanner.scanner(string).match i = 0 while True: m = match() if not m: break j = m.end() if i == j: break action = self.lexicon[m.lastindex-1][1] if callable(action): self.match = m action = action(self, m.group()) if action is not None: append(action) i = j return result, string[i:]
scanner是内置的SRE模式对象的一个属性,引擎通过扫描器,在找到一个匹配后继续找下一个。它基于SRE模式scanner构造,提供了一些更高一层的接口。
re模块中的scanner对于提升「不匹配」的速度并没有多少帮助,但阅读它的源码能告诉我们它是如何实现的:基于SRE的基础类型。它的工作方式是接受一个正则表达式的列表和一个回调元组。对于每个匹配调用回调函数然后以此构造一个结果列表。
re模块的源码到这里就结束了,虽然在源码文档开头有很大一部分注释是关于正则表达式用法的说明,但我觉得没必要在复制粘贴到这篇文章中,因为正则是通用的,和语言本身无关,网上一搜一大堆,就不再重复了。
总结:
在通读了re模块全文代码后,对于Python正则的认识也更深刻了,但是对于re引用的一些更加底层的模块如sre_parse和sre_compile.compile没有深入探究,以后再去学习。当然上面阅读的源码的理解仅限于我当前的水平。大家如果有觉得不对的地方,还望不吝赐教!我会及时更正并学习。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论