Python标准库源码阅读系列(一)–OS模块(上)
阅读Python标准库源码是我一直都有的一个计划,趁着暑假的时间。看了半个月OS模块的源码,反复分析做笔记,把文档中的一些注释也做了翻译。这也是一个提升。我这里用的是python 3.6的标准库源码。因为os模块的源码都很长且注释较多,所以我的想法是将其中每一段代码或者函数按顺序单独拿出来分析学习。由于篇幅太长,我将代码分析分为上下两部分。

首先还是从开头阅读源码,开头是一段注释,这里我就略过了,直接上代码。
import abc import sys, errno import stat as st _names = sys.builtin_module_names __all__ = ["altsep", "curdir", "pardir", "sep", "pathsep", "linesep", "defpath", "name", "path", "devnull", "SEEK_SET", "SEEK_CUR", "SEEK_END", "fsencode", "fsdecode", "get_exec_path", "fdopen", "popen", "extsep"] def _exists(name): return name in globals() def _get_exports_list(module): try: return list(module.__all__) except AttributeError: return [n for n in dir(module) if n[0] != '_']
开头这段代码,先导入了4个模块,sys大家都比较熟悉。
abc模块:python中并没有提供抽象类与抽象方法,但是提供了内置模块abc(abstract base class)来模拟实现抽象类。
errno模块:定义了许多的符号错误码, 比如 “ENOENT“ (“没有该目录入口”) 以及 “EPERM“ (“权限被拒绝”). 它还提供了一个映射到对应平台数字错误代码的字典。
stat模块:这个模块包含了一些 “os.stat“ 函数中可用的常量和测试函数。
sys.builtin_module_names 返回一个包含内建模块名字的元组,包含所有已经编译到Python解释器的模块名字。

然后定义了__all__。前面有一句注释意思是这里只定义了一部分,还有部分会在后面的代码添加到__all__中。
__all__属性,可用于模块导入时限制,如:from module import *
此时被导入模块若定义了__all__属性,则只有__all__内指定的属性、方法、类可被导入。若没定义,则导入模块内的所有公有属性,方法和类 。但它只对import *起作用,对from XXX import XXX不起作用。
接着定义了_exists函数,这个函数需要注意一下,他是返回True或者False。其中name in globals() 是一个表达式,name是形参,globals() 函数会以字典类型返回当前位置的全部全局变量,关键字in就是判断参数name是否在globals()中。不要误以为是把name放到全局变量里。
return xxx in xxx
我个人觉得算是一种比较优雅的写法,相比if更好。
_get_exports_list函数,通过传入模块名,获取模块中__all__定义的属性或方法,如果该模块没有定义__all__,则获取所有不是以下划线_开头的属性方法。因为通常_下划线开头的都属于私有成员变量方法。
[n for n in dir(module) if n[0] != ‘_’]
直接return这个列表推导式,不愧是标准库的代码,非常优美。
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
n[0] != ‘_’利用字符串切片,遍历整个模块,提取出不以下划线开头的变量方法名。
if 'posix' in _names: name = 'posix' linesep = '\n' from posix import * try: from posix import _exit __all__.append('_exit') except ImportError: pass import posixpath as path try: from posix import _have_functions except ImportError: pass import posix __all__.extend(_get_exports_list(posix)) del posix elif 'nt' in _names: name = 'nt' linesep = '\r\n' from nt import * try: from nt import _exit __all__.append('_exit') except ImportError: pass import ntpath as path import nt __all__.extend(_get_exports_list(nt)) del nt try: from nt import _have_functions except ImportError: pass else: raise ImportError('no os specific module found') sys.modules['os.path'] = path from os.path import (curdir, pardir, sep, pathsep, defpath, extsep, altsep, devnull) del _names
这里开始判断当前操作系统类型,_names是之前定义的内建模块。判断posix或者nt是否在元组里来判断操作系统。
posix代表类Unix系统,nt表示Windows系统。
在Windows中,python shell中执行

同理在linux中执行同样的语句则相反。
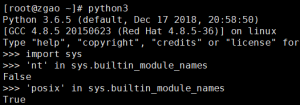
原理就是不同操作系统在安装Python环境时,windows有nt模块而没有posix模块,linux中则相反。
接着根据不同操作系统类型,定义不同的变量。
name表示操作系统类型。
linesep定义了当前平台使用的行终止符。例如,Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’。
在两个条件分支里
from posix import *
from nt import *
可以看得出os模块其实就是对posix或nt模块的二次封装,这样的好处就是实现了对不同平台的兼容。
import ntpath as path
sys.modules[‘os.path’] = path
而我们常用的os.path实际上是ntpath或者posixpath模块。之前我一直误以为os.path是os模块本身的。
sys.modules是一个全局字典,Python启动后就加载在内存中,记录新导入的模块。
if _exists("_have_functions"): _globals = globals() def _add(str, fn): if (fn in _globals) and (str in _have_functions): _set.add(_globals[fn]) _set = set() _add("HAVE_FACCESSAT", "access") _add("HAVE_FCHMODAT", "chmod") _add("HAVE_FCHOWNAT", "chown") _add("HAVE_FSTATAT", "stat") _add("HAVE_FUTIMESAT", "utime") _add("HAVE_LINKAT", "link") _add("HAVE_MKDIRAT", "mkdir") _add("HAVE_MKFIFOAT", "mkfifo") _add("HAVE_MKNODAT", "mknod") _add("HAVE_OPENAT", "open") _add("HAVE_READLINKAT", "readlink") _add("HAVE_RENAMEAT", "rename") _add("HAVE_SYMLINKAT", "symlink") _add("HAVE_UNLINKAT", "unlink") _add("HAVE_UNLINKAT", "rmdir") _add("HAVE_UTIMENSAT", "utime") supports_dir_fd = _set _set = set() _add("HAVE_FACCESSAT", "access") supports_effective_ids = _set _set = set() _add("HAVE_FCHDIR", "chdir") _add("HAVE_FCHMOD", "chmod") _add("HAVE_FCHOWN", "chown") _add("HAVE_FDOPENDIR", "listdir") _add("HAVE_FEXECVE", "execve") _set.add(stat) # fstat always works _add("HAVE_FTRUNCATE", "truncate") _add("HAVE_FUTIMENS", "utime") _add("HAVE_FUTIMES", "utime") _add("HAVE_FPATHCONF", "pathconf") if _exists("statvfs") and _exists("fstatvfs"): _add("HAVE_FSTATVFS", "statvfs") supports_fd = _set _set = set() _add("HAVE_FACCESSAT", "access") _add("HAVE_FCHOWNAT", "chown") _add("HAVE_FSTATAT", "stat") _add("HAVE_LCHFLAGS", "chflags") _add("HAVE_LCHMOD", "chmod") if _exists("lchown"): # mac os x10.3 _add("HAVE_LCHOWN", "chown") _add("HAVE_LINKAT", "link") _add("HAVE_LUTIMES", "utime") _add("HAVE_LSTAT", "stat") _add("HAVE_FSTATAT", "stat") _add("HAVE_UTIMENSAT", "utime") _add("MS_WINDOWS", "stat") supports_follow_symlinks = _set del _set del _have_functions del _globals del _add SEEK_SET = 0 SEEK_CUR = 1 SEEK_END = 2
这段代码调用之前的_exists函数。由于不同平台提供不同的功能,所以根据不同平台,判断支持的函数。
_set是一个集合,那么这个_have_functions是什么呢?回溯变量发现在之前的代码中。
from posix import _have_functions
from nt import _have_functions
继续回溯,发现该变量是一个列表,不同系统的值不一样。
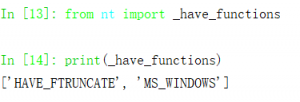
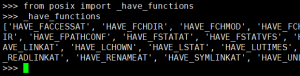
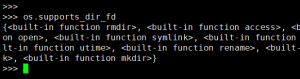
然后通过_add函数向集合中添加不同系统支持的函数。多次向_add传参之后将集合赋值给了新的变量。比如同样的os.supports_dir_fd

在windows中就是一个空集,而在linux中则非常多。
最后定义了三个SEEK常量,根据注释的意思是必要时他们被映射到posixmoudle.c中使用本机常量。
def makedirs(name, mode=0o777, exist_ok=False): head, tail = path.split(name) if not tail: head, tail = path.split(head) if head and tail and not path.exists(head): try: makedirs(head, mode, exist_ok) except FileExistsError: pass cdir = curdir if isinstance(tail, bytes): cdir = bytes(curdir, 'ASCII') if tail == cdir: return try: mkdir(name, mode) except OSError: if not exist_ok or not path.isdir(name): raise
接下来就是makedirs函数,他是对mkdir的封装。其实就是一次性创建一个子目录和所有中间目录。熟悉linux命令的朋友一定知道,这个功能就类似于mkdir的-p参数。
先分析path.split函数的作用。
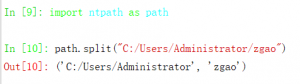
可见它是对传入路径的分割(以最后一个斜杆作为分隔),返回一个二元组。分别赋值给head和tail。当tail为空时再分割一次,即考虑到了传入参数数时结尾为斜杠的情况。
然后判断head是否存在,巧妙的利用异常捕获在try中递归调用自己,直到捕获到文件存在的异常来终止递归。而不是用if…else来判断,代码执行效率也更高了。
变量curdir的值就是一个点。在分析该函数时,我一直在纠结为何要判断tail是否为字节类型?
if isinstance(tail, bytes): cdir = bytes(curdir, 'ASCII')
查了资料后发现,Python3中的bytes和str类型。
Python 3最重要的新特性之一是对字符串和二进制数据流做了明确的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,你不能拼接字符串和字节流,也无法在字节流里搜索字符串(反之亦然),也不能将字符串传入参数为字节流的函数(反之亦然)。
因为考虑到传入的文件路径 xxx/newdir/. 和 xxx/newdirs 是等价的(别小看那个点,很细节)。
而传入的路径既可以是str类型,也可以是bytes类型。但是bytes的点和str的点是不相等的,所以要进行类型转换,否则无法return跳出递归,引发mkdir的报错。可见开发者考虑的十分全面,值得学习!
def removedirs(name): rmdir(name) head, tail = path.split(name) if not tail: head, tail = path.split(head) while head and tail: try: rmdir(head) except OSError: break head, tail = path.split(head)
现在再看removedirs函数的代码感觉会简单很多。先对传入路径删除一次,删除失败由rmdir引发报错,不过也只能向前删除空目录,实际可能用的很少。
def renames(old, new): head, tail = path.split(new) if head and tail and not path.exists(head): makedirs(head) rename(old, new) head, tail = path.split(old) if head and tail: try: removedirs(head) except OSError: pass __all__.extend(["makedirs", "removedirs", "renames"])
该方法用于递归重命名目录或文件。采用先创建后删除的方式。old — 要重命名的目录,new –文件或目录的新名字。甚至可以是包含在目录中的文件,或者完整的目录树。
有趣的是他实际是调用之前的两个函数,先创建第二个参数,再向前移除空目录。我认为应该在rename那里加上异常捕获的,由于makedirs调用在前,但是rename出错,新的文件夹还是作为了中间文件生成了。
不过我感觉这个函数不严谨,可能是因为我是做安全的吧,由于经常刷ctf,所以遇到这种函数,就可以拿来作为绕过,创建文件夹。比如我们要在当前目录下创建一个名为zgao的文件夹又不用mkdir该怎么实现呢?
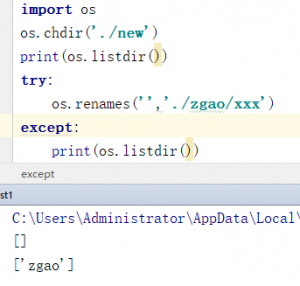
这样便实现了偷梁换柱。不过这只是我作为安全从业者的一些思考,不过这算题外话了。
接下来便是os模块里比较有名的一个函数了。相信很多人应该都用到过,os.walk()
def walk(top, topdown=True, onerror=None, followlinks=False): top = fspath(top) dirs = [] nondirs = [] walk_dirs = [] try: scandir_it = scandir(top) except OSError as error: if onerror is not None: onerror(error) return with scandir_it: while True: try: try: entry = next(scandir_it) except StopIteration: break except OSError as error: if onerror is not None: onerror(error) return try: is_dir = entry.is_dir() except OSError: is_dir = False if is_dir: dirs.append(entry.name) else: nondirs.append(entry.name) if not topdown and is_dir: if followlinks: walk_into = True else: try: is_symlink = entry.is_symlink() except OSError: is_symlink = False walk_into = not is_symlink if walk_into: walk_dirs.append(entry.path) if topdown: yield top, dirs, nondirs islink, join = path.islink, path.join for dirname in dirs: new_path = join(top, dirname) if followlinks or not islink(new_path): yield from walk(new_path, topdown, onerror, followlinks) else: for new_path in walk_dirs: yield from walk(new_path, topdown, onerror, followlinks) yield top, dirs, nondirs __all__.append("walk")
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
- top — 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
- topdown –可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
- onerror — 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
- followlinks –可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
逐步分析代码,先用fspath函数检测传入的路径是否为str或bytes类型。然后定义了dirs,nondirs和walk_dirs三个列表,也就是后面的三元组中的三个变量。然后调用scandir遍历,scandir方法返回了一个DirEntry迭代器对象,它非常轻巧方便。例如用scandir函数遍历当前目录。
在Python 3.5版本中,新添加了os.scandir()方法,它是一个目录迭代方法。你可以在PEP 471中找到关于它的一些内容。在Python 3.5中,os.walk是使用os.scandir来实现的,根据Python 3.5宣称,它在POSIX系统中,执行速度提高了3到5倍;在Windows系统中,执行速度提高了7到20倍。
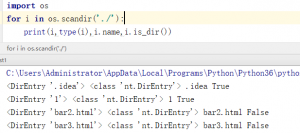
他返回的是一个DirEntry对象,用他的name属性获取到文件名,以及is_dir方法判断是文件还是目录。上面的代码也是这样判断后添加到不同的列表里。
然后再根据topdown参数的值决定是否递归到子目录,如果followlinks为False则将符号链接排除。注意符号链接并不是快捷方式,两者功能类似,但并不相同。
当引发异常时,判断onerror是否为空,如果有callable对象,则将异常作为参数传给该方法。由于scandir本身也是一个迭代器,所以用了with语句进行上下文管理。对这个不太熟悉的朋友可以参考我的另外一篇文章。
深入理解Python上下文管理-with语句
仔细观察if topdown之后的分支,因为walk这个函数本身就是一个生成器函数,所以这里用到了yield from的语法,后面跟的就是walk函数,实际上就是一个递归调用。思路非常清晰优秀!对yield用法不太熟悉的朋友可以参考这篇文章。
深入理解Python的yield from语法
所以walk这个函数实际是对scandir这个函数的封装。虽然很好用,但是效率也降低了很多,我个人认为在实际开发中可以直接用scandir来列目录,毕竟是C语言写的,运行速度会快很多。
if {open, stat} <= supports_dir_fd and {listdir, stat} <= supports_fd: def fwalk(top=".", topdown=True, onerror=None, *, follow_symlinks=False, dir_fd=None): if not isinstance(top, int) or not hasattr(top, '__index__'): top = fspath(top) orig_st = stat(top, follow_symlinks=False, dir_fd=dir_fd) topfd = open(top, O_RDONLY, dir_fd=dir_fd) try: if (follow_symlinks or (st.S_ISDIR(orig_st.st_mode) and path.samestat(orig_st, stat(topfd)))): yield from _fwalk(topfd, top, topdown, onerror, follow_symlinks) finally: close(topfd) def _fwalk(topfd, toppath, topdown, onerror, follow_symlinks): names = listdir(topfd) dirs, nondirs = [], [] for name in names: try: if st.S_ISDIR(stat(name, dir_fd=topfd).st_mode): dirs.append(name) else: nondirs.append(name) except OSError: try: if st.S_ISLNK(stat(name, dir_fd=topfd, follow_symlinks=False) .st_mode): nondirs.append(name) except OSError: continue if topdown: yield toppath, dirs, nondirs, topfd for name in dirs: try: orig_st = stat(name, dir_fd=topfd, follow_symlinks=follow_symlinks) dirfd = open(name, O_RDONLY, dir_fd=topfd) except OSError as err: if onerror is not None: onerror(err) continue try: if follow_symlinks or path.samestat(orig_st, stat(dirfd)): dirpath = path.join(toppath, name) yield from _fwalk(dirfd, dirpath, topdown, onerror, follow_symlinks) finally: close(dirfd) if not topdown: yield toppath, dirs, nondirs, topfd __all__.append("fwalk")
接下来的fwalk函数与上面的walk行为完全相同,只是他产生一个四元组。不过注意这里的两个函数是在定义在if条件分支之后的。函数的代码和上面是类似的,就不具体分析了。先分析这个分支条件的作用。
if {open, stat} <= supports_dir_fd and {listdir, stat} <= supports_fd:
需要注意的是这里的运算符并不是比较两个集合的数量大小,而是判断是否属于子集的关系。

这里比较有趣的一点是,我用的是pycharm。因为上面的那个判断为假,所以在nt平台下os模块是没有fwalk这个函数的,因为他是定义在这个分支下面的。
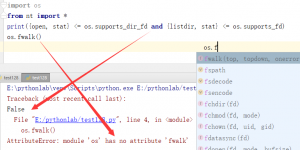
但是用pycharm写代码时,他的补全里还是有这个函数的。但是执行时才会报错提醒os模块没有该函数。算是一个小坑吧。可能是因为pycharm是从模块里全局读取这些方法,但是不会去管是否在分支或特定条件下定义的(个人理解)。
try: environ except NameError: environ = {} def execl(file, *args): execv(file, args) def execle(file, *args): env = args[-1] execve(file, args[:-1], env) def execlp(file, *args): execvp(file, args) def execlpe(file, *args): env = args[-1] execvpe(file, args[:-1], env) def execvp(file, args): _execvpe(file, args) def execvpe(file, args, env): _execvpe(file, args, env) __all__.extend(["execl","execle","execlp","execlpe","execvp","execvpe"])
os.exec*()这几个函数就不做具体分析。如果熟悉Unix下的系统编程的话,那么看到这些函数会觉得很熟悉,因为这些函数都是对相应的C API的Python实现。
这些函数都执行一个新的程序,然后用新的程序替换当前子进程的进程空间,而该子进程从新程序的main函数开始执行。在Unix下,该新程序的进程id是原来被替换的子进程的进程id。在原来子进程中打开的所有描述符默认都是可用的,不会被关闭。
execv*系列的函数表示其接受的参数是以一个list或者是一个tuple表示的参数表
execl*系列的函数表示其接受的参数是一个个独立的参数传递进去的。
exec*p*系列函数表示在执行参数传递过去的命令时使用PATH环境变量来查找命令
exec*e系列函数表示在执行命令的时候读取该参数指定的环境变量作为默认的环境配置,最后的env参数必须是一个mapping对象,可以是一个dict类型的对象。
os.exec*()都只是posix系统的直接映射,所以os.execl的第一个参数 “/usr/bin/python “是程序的可执行文件,而其他的都是program argument,就是c中int main(int argc,char** argv)中的argv。
而python的sys.argv应是c中argv的[1:],所以os.execl中的第二个参数 “python “对于python程序test.py不可见而且没有用。 实际上os.execl的第二个参数也就是int main(int argc,char** argv)中的argv[0]可以是任意的,它本质上是提供给c程序作为main()函数的第一个参数使用。
总结:
os模块源码分析,其实用的最多的也是这上半部分。由于源码太长,下半部分的代码分析我就放到另外一篇文章。上面代码分析中可以看的出开发者很多pythonic风格的代码值得我们学习,写这个源码分析也花了我很长的时间,把os模块的源码反复读了好多遍。虽然辛苦,但获益匪浅!
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
3条评论