绕过vip限制批量抓取某U学院app内音频资源
最近几天对app抓包有点上头,所以就研究了一些以前经常用到的app。首先这篇文章的涉及到的知识都很简单,我的本意是下学期我们学校网安协会要招新,也写一些简单实用的技术文章给刚入协会的小伙伴们。简单的十几行代码即可自行复现。

首先说一下这个app,是一个语言学习的app。因为我个人比较喜欢粤语,所以我之前就下载了他们粤语的app。不过这个app是收费的,我去年好像还真充过钱,后悔当时没有抓包分析,这样就不用充钱了。
因为并不复杂,所以就不是逆向分析脱壳什么的。只是对app的数据包请求抓取分析。因为是语言学习类的app,必然很多都是音频资源。所以我猜测多半都是直接向服务端请求音频资源,然后客户端再加载即可。如果没有对其加密则最好不过了。
我直接将apk拖到虚拟机安装,这里我用的网易的mumu模拟器,个人觉得还可以。进入到app页面内。
因为在没有登录或没充钱的情况,只能试学第一部分,而后面的内容就必须充vip才可以学习。所以为了方便分析,我还是先登录了我的vip账号。
接着开启我们的Charles抓包。随便进入一个短语学习的页面。
此时发现已经有一大堆音频的请求了。
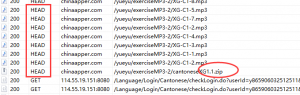
注意app内用的不是get,而是head。可以推测出app是为先判断该资源是否存在。细心发现还有一个zip压缩文件的请求。
其实做渗透的时候,就是要敢于大胆的推测开发者的思维逻辑。因为从命名上来看,我猜测那个zip就是这一段音频资源的合辑。
验证猜想直接复制url到浏览器,是可以直接下载的。解压出来看一下。

果然是音频资源,那么是不是开始有了骚思路。为了找规律,我们再多点击几个页面。然后在Charles中过滤出.zip后缀的请求。
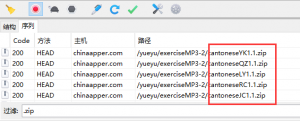
再次仔细观察每个文件名的区别。
都是中间两个大写的字母的组合,YQ,QZ,RC等等。
那么我们自己写脚本的话,如何构造出不同的url呢。我说一下我的思路。
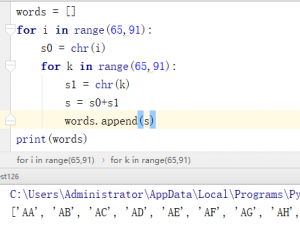
大家都知道ASCII码,每个字母都有对应的数字可以表示。Python内置函数chr()就是将数字转化为对应的字母。我用两个for循环来拼接出所有的字母组合构造为一个列表。
那么现在脚本就很简单了。直接上完整代码。
words = [] for i in range(65,91): s0 = chr(i) for k in range(65,91): s1 = chr(k) s = s0+s1 words.append(s) import requests f = open('yueyu.txt','a') for i in words: url = 'http://chinaapper.com/yueyu/exerciseMP3-2/cantonese{}1.1.zip'.format(i) r = requests.head(url) if r.status_code == 200: print(url) f.write(url+'\n') f.close()
同样用head方法筛选出为200的请求并把url写入到文件中。
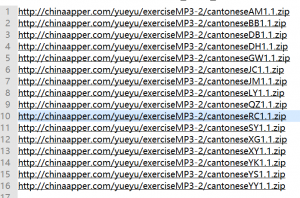
这个app内所有的音频资源就搞到手了。我发誓以后再也不充钱了,哈哈。
但是就这样结束,渗透狗思路还得再骚些才行啊。触类旁通嘛。看看这个app开发者的其他app应该也是用的同样的思路吧。那么

我在模拟器上把他们其他app也测了一下。结果
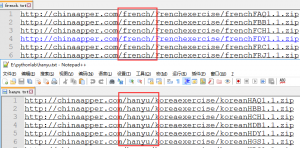
这也太快乐了吧。
现在直接写个shell脚本全部下载下来解压缩即可。也非常简单。
#!/bin/bash for url in $( cat yueyu.txt) do wget $url unzip $(basename $url) done
个人感觉shell写起来简单的就不用Python。
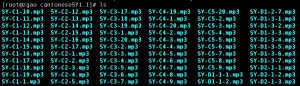
大功告成!
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
3条评论