看我如何优雅地收集大佬们的blog
因为平时自己经常写博客,也经常在网上查过很多资料文档,在这方面Google也算是帮了我不少忙。在Google上总能看到很多大佬们的博客,有很多优秀的文章值得自己学习。便萌生了一个搜集大佬们博客的想法,恰好在上一篇文章讲到过搭建Google镜像,借此把我的一些思路分享给大家。多认识些圈内的大佬,总归是有益的呢!

就我个人而言,平时看的文章比较多。每次看到优秀的博客,我总会记为书签保存下来。有空的时候把大佬们的文章都看一下,总能得到不少的收获。这里我主要分享3种方式,都很实用。
当然我这里所收集的博客主要是针对个人建站的那种独立博客。不是CSDN或简书那样的统一的平台。不知道为什么感觉用CSDN有点low,可能是有广告看着总觉得不舒服吧(纯属个人吐槽)。
1.基于github.io做二级域名查询
我相信很多朋友都喜欢用Github pages来搭建自己的博客,可能有的朋友还不太了解。
GitHub是一个非常重要和有用的社区,值得参与其中,Git / GitHub也是一个非常受欢迎的版本控制系统 – 现在大多数科技公司在其工作流程中使用它。 GitHub有一个非常有用的功能,称为GitHub Pages,它允许您在Web上实时发布网站代码。您可以将任何您喜欢的代码存储在Github资源库中,但要使用GitHub Pages功能实现全面效果,您的代码应该被构造为典型的网站。而且是免费的!!!虽然会有一些限制,但总得来说还是很棒了。
这里可以参考我朋友的一篇博客如何使用Github pages来搭建自己的博客。
hexo+github搭建个人炫酷博客
因为通过这种方式搭建的,都会有一个github.io的二级域名。搞安全的朋友都知道,在做信息收集时都会去找相关的二级域名。也正因如此,我们可以通过二级域名查找的方式来收集大佬们的博客。
网上有一些在线工具是非常好用的,比如这个网站
在线二级域名子域名查询
我们直接对github.io做二级域名查询。
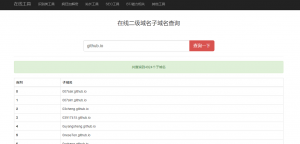
看到没,接近5000个哦。这是我发现的最简洁高效的收集方式。把他们全都保存下来,慢慢品读大佬们的文采,看到好的文章就应该去舔了,相信你懂的,哈哈。
2.基于Google镜像做文章关键词爬取
第一种方法虽说简单高效,但是却有局限性。很多大佬都是有自己独立的博客,但是大佬们博客的域名都是各式各样的,要想统一收集可真不是一件容易的事情。因为平时Google不离手,比国内的某度不知道良心到哪里去了。
本质就是将Google搜索到的结果进行二次提取,也就是写个爬虫来抓取URL链接,再用正则表达式来匹配提取,去除掉一些常见的网站,比如freebuf,安全客,阿里先知,看雪这些。因为基于文章关键词搜索,难免会出现很多平台的内容。
为什么要用Google镜像来做这件事呢?
平时经常用Google的朋友应该清楚那个验证码吧。它会各种问你:找出所有的大巴、红绿灯、消防栓、山峰……一轮又一轮。好了,向你确认完这件事后,话题就可以展开了——你真的以为你是在输入验证码?其实你是在给谷歌的无人驾驶和 数据标注 做义务劳动。
tm有的连我自己都认不出来。。。这个绕不过去就没法爬。所以这时Google镜像就能帮到我们不少,也正是前几天突发奇想,我为什么不用自己的Google镜像来做这件事呢!于是就有了这篇文章。
比如我们以 Redis未授权访问 来作为关键词进行搜索,会得到如下内容。
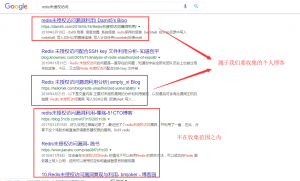
然后我们对页面元素进行审查。在页面源码中可以看到
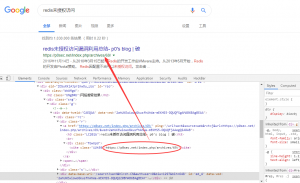
发现所有的URL都是cite标签内的,而标题都是用的h3标签。那么这下就简单了。当然还有其他的分析过程,比如说分页什么的,我就不再赘述了,直接上我已经写好了的代码。
import requests from bs4 import BeautifulSoup import re from pprint import pprint print('\t基于关键词搜索的博客URL爬虫 --Author by:Zgao') url_list =[] knwon_list = ['jianshu.com','github.com','juejin.im','aliyun.com','anquanke.com','freebuf.com','toutiao.io','csdn.net','bugbank.cn', 'kanxue.com','seebug.org','youtube.com','zhihu.com','v2ex.com','tencent.com','baidu.com','sobug.com','bilibili.com', 'google.com','linkedin.com','pediy.com','douban.com','gitee.com','cnblogs.com','ichunqiu.com','51cto.com','tuisec.win', 'secpulse.com','qq.com','360.cn','imooc.com','bbs'] str_input = input('请输入关键词:') page = int(input('请输入爬取页数:')) for m in range(1,page+1): r =requests.get('http://cdtu.fun/search?q={}&start={}'.format(str_input,str(m*10))) soup = BeautifulSoup(r.text,'lxml') tag = soup.find_all('a') for i in tag: try: url = re.search('http[s]://.*?/',str(i)).group() url_list.append(url) for k in knwon_list: if k in url: url_list.pop() break except: pass print('正在抓取第{}页!'.format(str(m))) url_set = set(url_list) pprint(url_set)
这里用到的就是我自己的Google镜像。运行结果如图
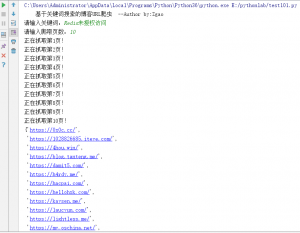
这里对上面的代码做一些解释,knwon_list这个列表是就是对一些常见的域名进行过滤,可自行添加,删减。当然这里得到结果也不一定完全准确,还需自行检验,不过大部分都还算准确。毕竟亲自点开各位大佬的博客看看也是有好处的哦!
3.别忘了 “友链”
一个优秀的人,他周围总是有一群和他一样优秀的人
这个我相信大部分朋友应该都会知道吧。友链这个东西,也是我每次看别人的博客必定会关注的东西。大佬们的友链想必也有很多大佬吧。这就不用我多说了吧。
以上就是我平时收集大佬们博客的方法了。第一二种都是我自己想出来的,个人感觉还算不错。大家平时多和优秀的人在一起,向优秀的人学习借鉴。自己也会变得更优秀的!如果大家还有什么更好的方法欢迎和我交流,我也会在文中加上去的。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
2条评论