抓取斗鱼(虎牙)平台各大游戏主播数据的爬虫源码分析
这个爬虫本身是前几天帮朋友写的,是爬取虎牙上的各类游戏top 10 的主播。不过写完后,又把代码重写了一份,顺便把斗鱼上各类游戏主播的数据也抓取了一下。结果发现斗鱼的爬虫代码更具代表性,而且效率非常之高。所以便有了这篇文章。

按照我的风格,不bb直接上源码。使用该源码前需要安装的第三方库有requests,pymysql,bs4,lxml.当然不用数据库的话,可以选择写入到一个文本文件中。
#!/usr/bin/python3 import requests import datetime import pymysql from bs4 import BeautifulSoup #连接数据库 db = pymysql.Connect('服务器ip', '用户名', '密码', '数据库名') #自行填充 cursor = db.cursor() #获取斗鱼所有的直播分类 html = requests.get('https://www.douyu.com/directory') soup = BeautifulSoup(html.text,'lxml') li = soup.find_all('li') #遍历所有的li标签 for tag in li: if tag.img and tag.div: href = 'https://www.douyu.com' + tag.a['href'] name = tag.p.string r = requests.get(href) soup_1 = BeautifulSoup(r.text, 'lxml') p = soup_1.find_all('li') for i in p: try: if i.img: room_url = 'https://www.douyu.com' + i.a['href'] zhubo_name = i.p.span.string zhubo_looking = i.p.find_all('span')[1].string room_title = i.h3.string.replace(' ', '') looking = i.find_all('div')[2].find_all('span') time_now = str(datetime.datetime.now())[:-7] zhubo_tag = [] for n in looking: zhubo_tag.append(n.string) zhubo_tag = ','.join(zhubo_tag) sql = "insert into gameinfo (游戏名称,主播,当前热度,房间标题," \ "主播标签,房间url,抓取时间) VALUES ('%s','%s','%s','%s'," \ "'%s','%s','%s')" % (name, zhubo_name, zhubo_looking, room_title, zhubo_tag, room_url, time_now) cursor.execute(sql) db.commit() print(sql) except Exception: pass db.close()
整个爬虫的思路分析
1.先抓取所有的游戏分类所对应的url
2.得到各类游戏页面内数据
3.对数据进行清洗和处理,提取出我们需要的信息,包括 游戏名称,主播,当前热度,房间标题,主播标签,房间url
4.将这些信息构造成sql语句写入到数据库中
5.循环遍历所有游戏,重复上面的过程
现在我们对整个爬虫代码进行分析。
要获取所有的游戏分类,我们直接去get分类这个页面。
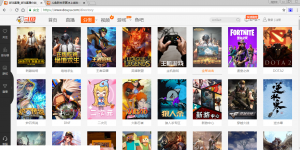
去分析该页面的源码。
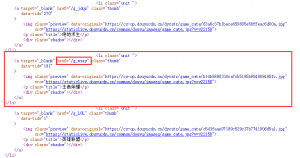
可看到所有的游戏都是放在li标签中的,所以遍历源码中的所有li标签。但是这里有一点要注意就是页面中除了各类游戏使用了li标签,还有其他的li。但是我们只需要包含游戏的标签,所以在代码中加入了一个判断。
for tag in li:
if tag.img and tag.div:
选出li标签中同时含有img和div标签的,便是我们需要的。在for循环中,get各个页面的信息,下面我以游戏吃鸡为例,来分析数据的提取。
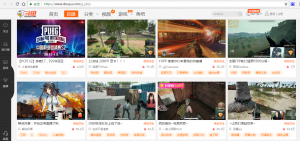
我们需要提取的信息有 游戏名称,主播,当前热度,房间标题,主播标签,房间url。同样先观察页面的源码

同样还是放在li标签中的,在第二层的for循环中虽然用了if i.img来判断,但还是会提取出一些不需要的标签,所以我们就可以用捕捉异常try来忽略掉那些不包含信息的标签。
可能需要补充的一个知识点是.string 属性
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点。如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同。
通俗点说就是:如果一个标签里面没有标签了,那么 .string 就会返回标签里面的内容。如果标签里面只有唯一的一个标签了,那么 .string 也会返回最里面的内容。如果tag包含了多个子节点,tag就无法确定,string 方法应该调用哪个子节点的内容, .string 的输出结果是 None。

由于考虑到每个主播的标签个数会不一样甚至是没有,所以在提取主播便签的时候用了一个列表来存放。
zhubo_tag = [] for n in looking: zhubo_tag.append(n.string) zhubo_tag = ','.join(zhubo_tag)
在列表中依次增加每个span标签的内容,然后用逗号分隔将整个转换为一个字符串。
接着就是构造sql语句写入数据库,就是常规操作了。再依次遍历下去。知道抓取完所有的游戏分类。整个过程只有几分钟的时间,便爬取了6000多条数据的样子。
顺便将虎牙的爬虫代码给出来,思路都是相同的。感兴趣的小伙伴可以拿去玩玩哦!
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup
import pymysql
import re
import datetime
db = pymysql.Connect('服务器ip', '用户名', '密码', '数据库名') #自行填充
cursor = db.cursor()
html = requests.get('https://www.huya.com/g')
soup = BeautifulSoup(html.text,'lxml')
li = soup.find_all('li')
for i in li:
try:
url = i.a['href']
if i.h3.string:
name = i.h3.string
yy = requests.get(url)
soup_2 = BeautifulSoup(yy.text, 'lxml')
p = soup_2.find_all('li')
for n in p:
if n.img:
room_url = n.a['href']
zhubo_name = n.img['alt'][0:-3]
room_title = n.find_all('a')[1].string
looking = n.find_all('span')[2].find_all('i')[1].string
r = requests.get(room_url)
soup_1 = BeautifulSoup(r.text, 'lxml')
div = soup_1.find_all('div')
a = re.search('Count.*<', r.text).group()[7:-1]
time_now = str(datetime.datetime.now())[:-7]
sql = "insert into gameinfo (游戏名称,主播,房间标题,当前观看量," \
"当前订阅量,房间url,抓取时间) VALUES ('%s','%s','%s','%s'" \
",'%s','%s','%s')" % (
name,zhubo_name,room_title,looking,a,room_url,time_now)
cursor.execute(sql)
db.commit()
print(sql)
except Exception:
pass
db.close()

由于虎牙和斗鱼不同,不是按照热度来判断的,所以就同时抓取了当前观看量和订阅量。而订阅量只有在主播的直播间内才有,所以导致虎牙爬取的速度就慢了不少。
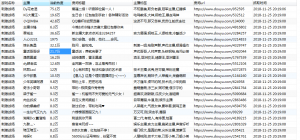
不过由于只抓取一次可能存在偶然性,每天爬取一两次,需要连续爬取一段时间,所以分析这些数据的过程就放在我的下一篇文章中了。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论