分享一个自己写的C++代码混淆工具(附源码)
本来写这个工具的想法是绕过我们专业的专周数据结构的作业查重,因为我本身不会C++,但是直接copy别人的代码会被查重而且也没什么技术含量,所以我就用python写了一个混淆代码的脚本,成功给绕过去了。写完之后发现这个混淆工具其实还蛮不错的,所以就想把他分享给大家。
这个工具混淆的思路其实是来源最近github上一个特别火的项目eeeeeeeeeeeeeeeeeeeeeeee。然后在好友蒋大佬的协助下完成的,在这里先感谢蒋大佬。
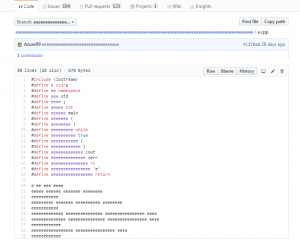
其中C++那部分的代码就是长这样的。其原理就是用define一个字符串来代替了原有的字符。
引用网上对define的解释。
C语言中,可以用 #define 定义一个标识符来表示一个常量。其特点是:定义的标识符不占内存,只是一个临时的符号,预编译后这个符号就不存在了。
预编译又叫预处理。预编译不是编译,而是编译前的处理。这个操作是在正式编译之前由系统自动完成的。
用 #define 定义标识符的一般形式为:#define 标识符 常量 //注意, 最后没有分号
#define 和 #include 一样,也是以“#”开头的。凡是以“#”开头的均为预处理指令,#define也不例外。
#define又称宏定义,标识符为所定义的宏名,简称宏。标识符的命名规则与前面讲的变量的命名规则是一样的。#define 的功能是将标识符定义为其后的常量。一经定义,程序中就可以直接用标识符来表示这个常量。是不是与定义变量类似?但是要区分开!变量名表示的是一个变量,但宏名表示的是一个常量。可以给变量赋值,但绝不能给常量赋值。
宏所表示的常量可以是数字、字符、字符串、表达式。其中最常用的是数字。
那么,程序中什么时候会使用宏定义呢?用宏定义有什么好处呢?我们直接写数字不行吗?为什么要用一个标识符表示数字呢?
宏定义最大的好处是“方便程序的修改”。使用宏定义可以用宏代替一个在程序中经常使用的常量。注意,是“经常”使用的。这样,当需要改变这个常量的值时,就不需要对整个程序一个一个进行修改,只需修改宏定义中的常量即可。且当常量比较长时,使用宏就可以用较短的有意义的标识符来代替它,这样编程的时候就会更方便,不容易出错。因此,宏定义的优点就是方便和易于维护。
那么程序在预编译的时候是怎么处理宏定义的呢?或者说是怎么处理预处理指令的呢?
其实预编译所执行的操作就是简单的“文本”替换。对宏定义而言,预编译的时候会将程序中所有出现“标识符”的地方全部用这个“常量”替换,称为“宏替换”或“宏展开”。替换完了之后再进行正式的编译。所以说当单击“编译”的时候实际上是执行了两个操作,即先预编译,然后才正式编译。#include<stdio.h>也是这样的,即在预处理的时候先单纯地用头文件stdio.h中所有的“文本”内容替换程序中#include<stdio.h>这一行,然后再进行正式编译。
需要注意的是,预处理指令不是语句,所以后面不能加分号。这是很多新手经常犯的错误。#include 后面也没有加分号。
所以当时我就想能否自己写一个脚本自动将c++混淆成类似的代码,一方面可以绕过查重,另一方面也可以不让别人轻易看懂你写的代码。
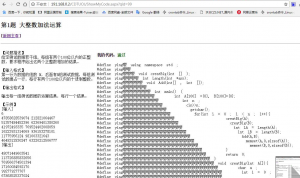
这个是最开始用脚本混淆后的代码,这种方式是采用直接一个字符串来代替一行,通过是肯定可以的。但是代码并没有给隐藏起来所以接下来我就修改了脚本混淆每一个字符,
我就把这个脚本编写的思路分享给大家。
- 先读取cpp代码的源文件,将每一行的内容存放到一个列表中。
- 将C++里面所有的关键字所有的字符(包括,;. () {} :等等)这些都写到一个列表中去。
- 在两个for循环中进行遍历,第一重循环遍历源码的每一行,第二重循环遍历查找是否有字符列表中的字符,如果有就进行替换。再写入到新文件中去。
- 在ascii码表中找一个范围,随机生成一个首字母来作为替换的内容。
- 再加入一些随机的注释,让混淆后的代码看起来更乱。
import random import string keyword_list = ['cout','+=','-=','int ','goto','asm', 'do', 'if','[',']', 'return', 'typedef', 'auto', 'double', 'inline','{','}', 'short', 'typeid', 'bool', 'int ','(',')', 'signed', 'typename', 'break', 'else','>=','<=', 'sizeof', 'union', 'case', 'enum', 'mutable',';', 'static', 'unsigned', 'catch', 'explicit', 'try', 'namespace', 'using', 'char','main','const', 'export', 'new', 'struct', 'class', 'switch', 'false', 'private', 'long','::', 'void','endl', 'float', 'protected', 'this', 'continue','++','--', 'for', 'public', 'throw', 'while', 'default', 'friend', 'true','<<','cin','printf','==','>>','!=',] def random_char(): r = chr(random.randint(97,122)) char,char_r,list_chr = [],[],[] for i in range(len(keyword_list)): char.append(r+str(i)) char_r.append(keyword_list[i]) random.shuffle(char) random.shuffle(char_r) for i in range(len(char)): list_chr.append([char[i],char_r[i]]) return list_chr def generate_define(list_chr): define = [] for i in range(len(list_chr)): define.append('#define '+ list_chr[i][0] +' '+list_chr[i][1]) return define def replace(list_char,str,confusion): if confusion == ' /**/ ': confusion = ' /*' + ''.join(random.sample(string.hexdigits,6)) +'*/ ' for i in list_char: if i[1] in str: str = str.replace(i[1],confusion+i[0]+confusion) return str def open_file(list_char): cpp = input('请输入一个C++代码的文件名:') confusion = input('请输入混淆注释(可选,不填则随机混淆):') confusion = ' /*' + confusion + '*/ ' filenmae = cpp.split('.')[0]+'混淆.cpp' with open(cpp,'r') as f: with open(filenmae, 'w') as m: define = generate_define(list_char) for i in define: m.write(i+'\n') for i in f.readlines(): if '#' in i[0]: m.write(i) continue i=i.strip() i_replace = replace(list_char,i,confusion) m.write(i_replace+'\n') print('混淆代码完成了哦^_^!\n混淆后的文件名为: '+filenmae+'\n') if __name__ =='__main__': print('-' * 60) print(' C++ 代码混淆工具beta版 Author By: Zgao\n') print(' tips: cpp代码和该软件需在同一目录下\n') print('-'*60) while True: open_file(random_char())
这是整个工具的源码,列表中的关键字可能并不全,但是已经包括较大部分,可自行修改。
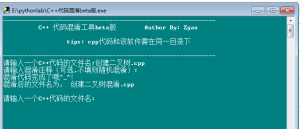
这是打包生成exe的使用截图。链接:https://pan.baidu.com/s/1KzSV_jqd1bfbwf4kBpikKg
提取码:xywi
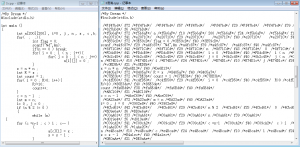
代码混淆前后对比,对编译无任何影响,只是让人无法轻易读懂你的代码。所以把源码分享出来,如果大家在使用中遇到了什么bug或疑问,欢迎和我交流哦!
赞赏
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
7条评论