老齐的IT加油站–视频接口抓取思路分析
写这篇博客呢,也是一个偶然。昨天晚上杨勇老师在我们专业群里分享了一些学习资源。但是这些视频是收费的,不过恰好有一位同学已经差不多买完了,所以就可以大家共享账号一起学习。后面想了想我能不能把老齐所有的付费视频给抓取下来呢,经过一上午的摸索,还是不错的呢。
![]()
当然事情一开始是这样的。
而我属于那种吃瓜群众。大家共享账号其实也挺好的,不过后面杨勇老师说共享账号别人改了密码什么的,想想可能是不太好。反正这位同学都把视频给买了,每天都在搞py的我不如分析一波,看能不能搞到原视频的url,把视频全部给打包下载下来,想着想着就打开了我的pycharm,逛起了老齐的加油站。
随便点开了一个视频页面。
前面有一些免费的,我自己也看了一些,感觉老齐人其实挺良心的,是用心做的教学视频。
不废话,直接开始分析,f12打开开发者工具。
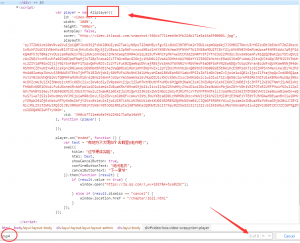
我先在整个网页源码里搜索关键字mp4,发现并没有。想想要是这么简单就找到了,那还需要分析干嘛。其中图中的js引起了我的注意 Aliplayer
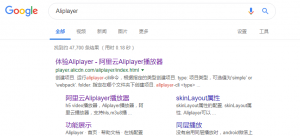
赶紧Google了一下,原来是阿里的播放器。那么要想拿原视频的url多半的从这里下手。所以我就研究了一下阿里的这款播放器,恰好其中有一个在线配置的功能。
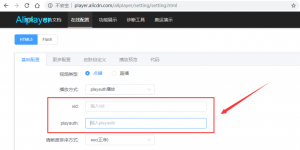
其实仔细观察上面的那段js,会发现vid和playauth的值都已经给出了,天真的我以为,要不我直接把那段js里对应的值给复制过去,就播放视频呢,由此解析出url。
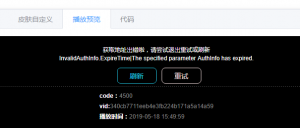
果然是too young too simple。这个思路不行。但是峰回路转,为什么我不先播放一下视频呢??我转到了network。
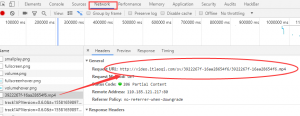
顿时豁然开朗,要播放视频,必然会向视频的url发起请求,不管它是通过直接请求,ajax,js什么的方式,这个网络请求的过程是必定会有的。
虽然分析了之后发现这个请求是由aliplayer-min.js发起的。
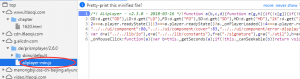
本来也想去分析一下的,看能不能我自己注入js去hook这个js中的关键函数,只要把请求拦截下来,就能拿到url了。
这个想法是挺好的,然而这个js看着看着我就自闭了。。。

算了,还是我太菜了。换个思路,反正这个请求都会出现在浏览器的network请求中,不如我就去拦截selenium的请求数据吧,发现这个想法可行。这里我先贴出我的代码
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.desired_capabilities import DesiredCapabilities import re import time import json caps = DesiredCapabilities.CHROME caps['loggingPrefs'] = {'performance': 'ALL'} driver = webdriver.Chrome(desired_capabilities=caps) with open('num.txt','r')as p: num = p.readlines() f = open('url.txt','w+') def login(): driver.get('http://www.itlaoqi.com/login.html') driver.find_element_by_xpath('/html/body/div/div/div[2]/div/form/div[2]/input').send_keys('CDTU杨小樟') driver.find_element_by_xpath('/html/body/div/div/div[2]/div/form/div[3]/input').send_keys('密码') driver.find_element_by_xpath('//*[@id="btnSubmit"]').click() time.sleep(5) def get_url(): for i in num: try: driver.get('http://www.itlaoqi.com/chapter/{}.html'.format(str(i.strip()))) driver.find_element_by_tag_name('body').send_keys(Keys.SPACE) time.sleep(5) lo = driver.get_log('performance') for entry in lo: try: m = str(json.loads(entry['message'])['message']["params"]) url = re.search('http://video.itlaoqi.com/sv/.*?mp4', m).group() print(url) f.write(url + '\n') break except Exception as e: continue except: pass finally: f.close() if __name__ == '__main__': login() get_url()
其中的login函数是用来模拟登录的,主要是我太懒了,本来我可以从已有的已登录的页面复制cookie过去但是,浏览器的cookie是字符串格式的,但selenium添加cookie要用字典的格式,我不想多写一个转换的函数,就这样吧。反正老齐的网站登录时也没加验证码。
这个是使用上面login函数执行的。主要的抓取在get_url函数中
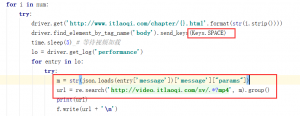
也就是这部分。将selenium的网络请求转换为json格式的数据,经过分析在params中。但是这里我之前遇到一个问题,我觉得还是很有意思的。
因为每个视频的页面加载后,视频是不会直接播放的,需要去点击播放的按钮。虽然selenium模拟点击不是什么难事,但是那个播放的按钮,我用元素始终定位不到,而且定位到了,点击会报错。我试了好几次,无果。只能换个办法,难道非得让我注入js执行??
我又去看了看上面的那段js代码。有了新的发现。
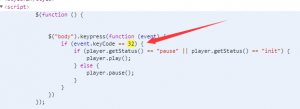
我看到了event.keyCode == 32,这不就是键盘事件监听吗。看到32我脑中闪现的这是ascii码啊,不就是 空格 吗?
这不就是通过监听space来控制视频的播放和暂停嘛。老齐这不是在帮我忙吗,哈哈。我send一个space过去不就可以播放视频了。
所以这个坎算是绕过去了。接下来的也不难了,要想最快提取出url的办法就是将json转化为str,直接正则匹配就好了,毕竟格式是统一的。
就这样我顺利地抓取到了第一个视频的url,但是我们的目的是批量抓取。所以接下来的就是要抓取所有的视频页面了。
我猜接下来大家的想法应该是这样的,先去抓取所有视频的首页,写个for循环,取出所有的播放页面的值放到列表里。
这种思路是最典型的思路,无可厚非。但是作为一只渗透狗,思路当然要更骚一点才行啊。仔细观察。

对于这种连续的,我自己思考出了一种巧妙的方法。
如何做到四两拨千斤呢?
利用服务器报错信息快速抓取!
比如我们在老齐的网站上打开一个不存在的视频页面,会是这样。
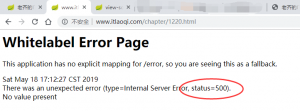
看到了吗,服务器报错了。状态码是500。而一个正常页面应该是200才对。
继续观察,我最终发现所有的视频id大致处于一个(1300,1650)这样一个区间内。
那么我们现在就可以开始遍历了。
import requests with open('num.txt','w') as f: for i in range(1300,1650): r = requests.head('http://www.itlaoqi.com/chapter/{}.html'.format(str(i))) if r.status_code == 200: f.write(str(i)+'\n') print(i)
凡是http状态码为200的,我们就写入到文件中保存下来,而且这个速度非常快。 好的思路有时真的能给我们减少很多代码量和大量时间。
现在再运行上面的代码就能批量抓取到视频url了,也就像这样吧。
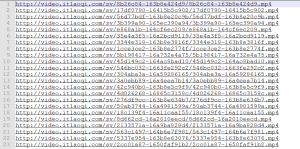
现在抓取到了视频url,那么基本上算大功告成了。
接下了就是扔到服务器里批量下载了,不过这里一开始也遇到了些小问题。我本来就不安分,想看看老齐的服务器能不能列目录,虽然基本上是不肯的,但还是试了试。
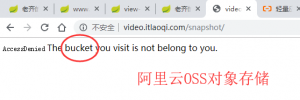
看到bucket这个单词时我秒懂了,这个域名指向的不是老齐的服务器,而是阿里的oss,一般用来存放静态资源的。
因为我只会玩linux服务器,所以想了想要不直接写个写个脚本来批量下载吧,反正wget也好用,之前做小米运维的面试题的时候也写过类似的。
#!/bin/bash if [ $# -eq 0 ];then echo "./downlaod.sh url.txt" exit 1 fi if [ ! -f $1 ];then echo "Input file not found!" exit 2 fi for url in $(cat $1 ) do wget $url done
然而404什么鬼 ? ?
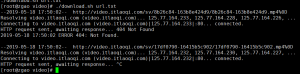
我也很懵逼,但是浏览器打开链接是正常的。
import requests with open('url.txt','r')as f: for i in f.readlines(): i = i.strip() filename = i.split('/')[-1] print(filename) r = requests.get(i) print(r.status_code) with open(filename,'wb') as e: e.write(r.content)
所以还是换了python来写下载,虽然本质是相同的,但是为什么Python能正常下载,一开始我以为是header的缘故,结果wget加了header也是一样的。那么之后再分析原因吧,也许是阿里云oss做了什么限制。
因为都是阿里云的服务器,没有写多线程,也没下多久就下完了,总共差不多9个多G。
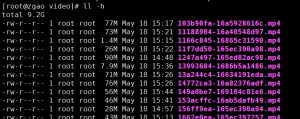
这个视频接口分析的过程差不多就这些了。
最后我想说的话:
虽然我也是通过技术手段下载了这些视频,但是我只打算分享给我们专业的同学一起学习。就不公开分享给大家了,这算是对老齐尊重吧,老齐用心良苦做这些教程,挣钱也不容易。而且教程本身也不贵,大家还是支持一下老齐吧,尊重知识版权。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
2条评论