AWS S3(存储桶)理论基础和应急排查思路
在云上应急响应和安全运营场景中,AWS S3 几乎是绕不开的核心基础设施之一。
Amazon S3(Simple Storage Service)是 AWS 提供的对象存储服务,主打高可用、高可靠、可无限扩展。从企业日志、业务数据,到备份、镜像、取证文件,很多关键数据最终都会落在 S3 上。
也正因为它“什么都能存”,一旦配置不当,S3 也是云上数据泄露、勒索攻击、取证对抗中最常被利用的点之一。
S3 的理论基础
S3 的核心概念并不复杂:
- Bucket(桶):逻辑上的存储容器
- Object(对象):文件本身 + 元数据
- Key:对象在 Bucket 内的唯一标识
在实际使用中,你会先创建一个 Bucket,指定区域,然后把数据以对象的形式上传进去。
从应急视角来看:
Bucket = 一个潜在的数据资产边界
Object = 可能包含敏感信息的证据或泄露源
默认是“安全”的,但也最容易配置出错
S3 默认是私有的,但访问控制非常灵活,也非常容易被误配置。
常见的访问控制方式包括:
- Bucket Policy
- IAM Policy
- ACL(访问控制列表)
- S3 Access Points
从实战案例来看,绝大多数 S3 泄露事件,问题不在 S3 本身,而在权限配置。
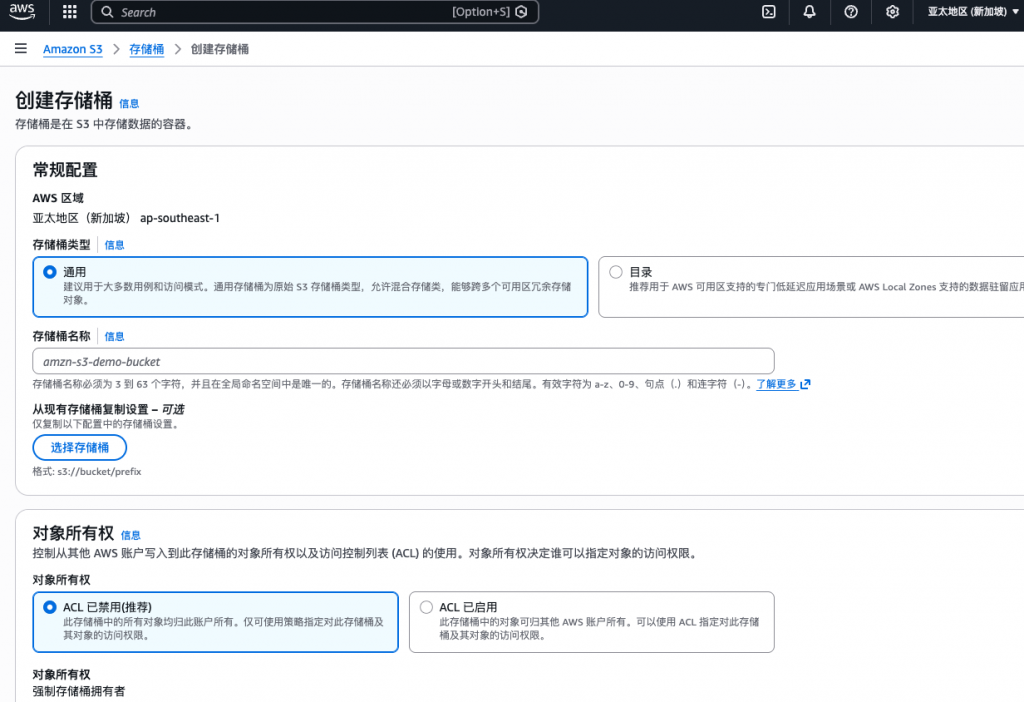
创建和配置 S3 Bucket的注意点
创建 Bucket 本身很简单,但真正决定安全性的,是后续配置。常见关键配置项:
版本控制(Versioning)
- 建议对核心数据开启
- 是应对误删、勒索的重要防线
S3 支持对象版本控制,可以理解为类似git的版本控制。这是对抗误操作和勒索攻击的核心能力之一。

当然,它会带来额外成本,建议优先用于备份 Bucket,存放关键业务数据的 Bucket。
访问日志(Logging)
S3 支持记录访问日志,能看到:
- 谁访问了
- 什么时候访问
- 做了什么操作
从应急角度讲:不开日志的 S3,出了事基本等于“盲飞”。日志建议投递到独立 Bucket,甚至独立账号。
对象所有权 与 ACL:一个经常被忽略的坑
AWS 现在推荐的默认模式是 Bucket owner enforced:
- 禁用 ACL
- 统一通过 IAM 和 Bucket Policy 管理权限
这是一个对安全非常友好的默认值。
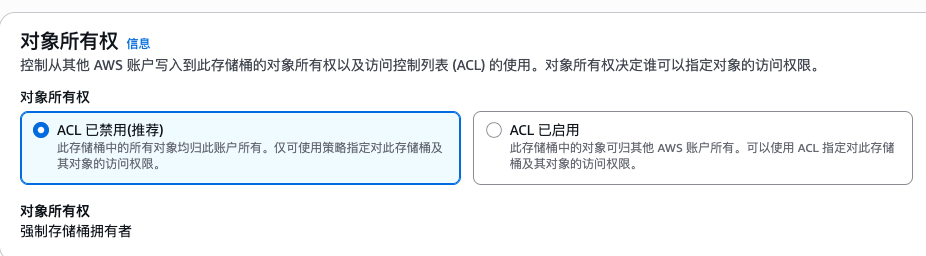
很多人会下意识地认为“Bucket 是我的,里面的对象自然也是我完全可控的”,但在开启 ACL、并将 Object Ownership 设为 Object writer 的情况下,这个认知是错误的。此时,对象的真正所有者是“上传它的账号”,而不是 Bucket 的拥有者。
现实中的结果是:当外部账号、第三方服务或跨账号系统向你的 Bucket 写入对象后,这些对象可能并不受你的 Bucket Policy 控制。应急场景下,你可能会发现自己无法删除可疑文件、无法修改对象权限,甚至无法立即阻断数据访问,严重拖慢止血速度。
所以AWS 现在强烈推荐使用 Bucket owner enforced 模式,彻底禁用 ACL,让所有对象自动归 Bucket 所有者统一管理,将权限控制收敛到 IAM 和 Bucket Policy,这对安全运维和应急响应来说至关重要。
一旦涉及跨账号、ACL 混用,溯源和处置难度会指数级上升。这是在实战应急中真实遇到过的案例。
严格限制 S3 的公共访问
在实际的云上应急响应中,S3 往往不是攻击的起点,但经常是事故的放大器。数据泄露、勒索攻击、恶意托管、取证失败,很多事件最终都会追溯到 S3 的权限、日志或加密配置上。因此,S3 的安全建设,本质上是一项事前防护 + 事中发现 + 事后取证的系统工程。
在组织层面,控制哪些 Bucket 可以公开,远比“发现谁已经公开”更重要。
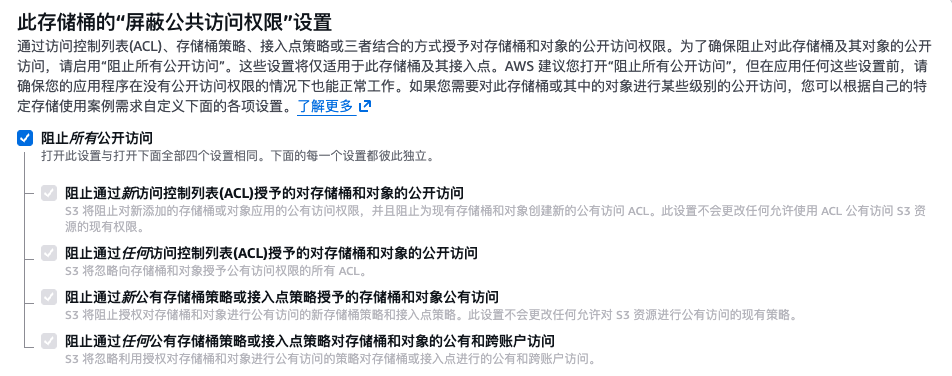
AWS 提供了 S3 Block Public Access 机制,可以在以下层级统一阻断公共访问:
- 账号级
- Bucket 级
- 未来新建的 Bucket
在真实事故中,很多 S3 泄露并不是“被攻击”,而是“被自己配置错”。
CloudTrail 监控和日志
在云上应急响应中,有一句话几乎是共识:
没有监控和日志的系统,不是“暂时没出事”,而是“出事了但无法感知道”。
对于 Amazon S3 来说, 本身高度稳定,很少“自己出问题”,但一旦发生数据泄露、误配置或恶意访问,是否能快速定位责任、范围和影响,全靠监控和日志。
CloudTrail:S3 事件溯源的第一入口
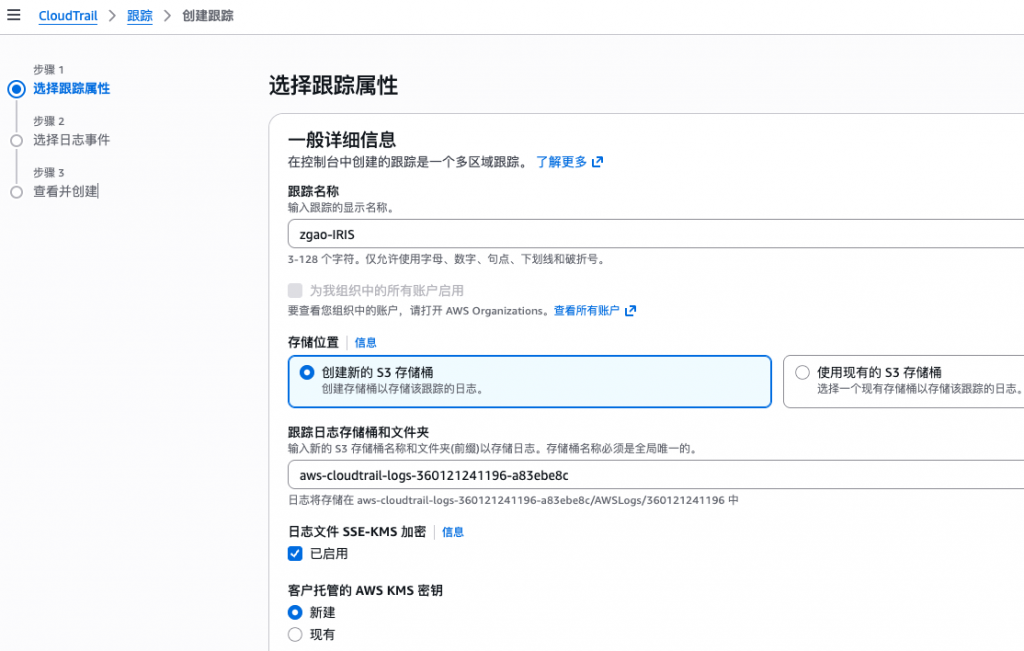
如果只能为 S3 选一个“必开”的日志,那一定是 CloudTrail。CloudTrail 会记录:
- 谁(用户 / 角色 / 服务)
- 在什么时间
- 从哪里(IP、Region)
- 对 S3 发起了什么 API 请求
在应急响应中,它通常能解决最关键的几个问题:是不是有人在动这个 Bucket?访问是来自内部还是外部?是人工操作、脚本,还是被某个服务调用?
CloudTrail 对 S3 的正确开启方式
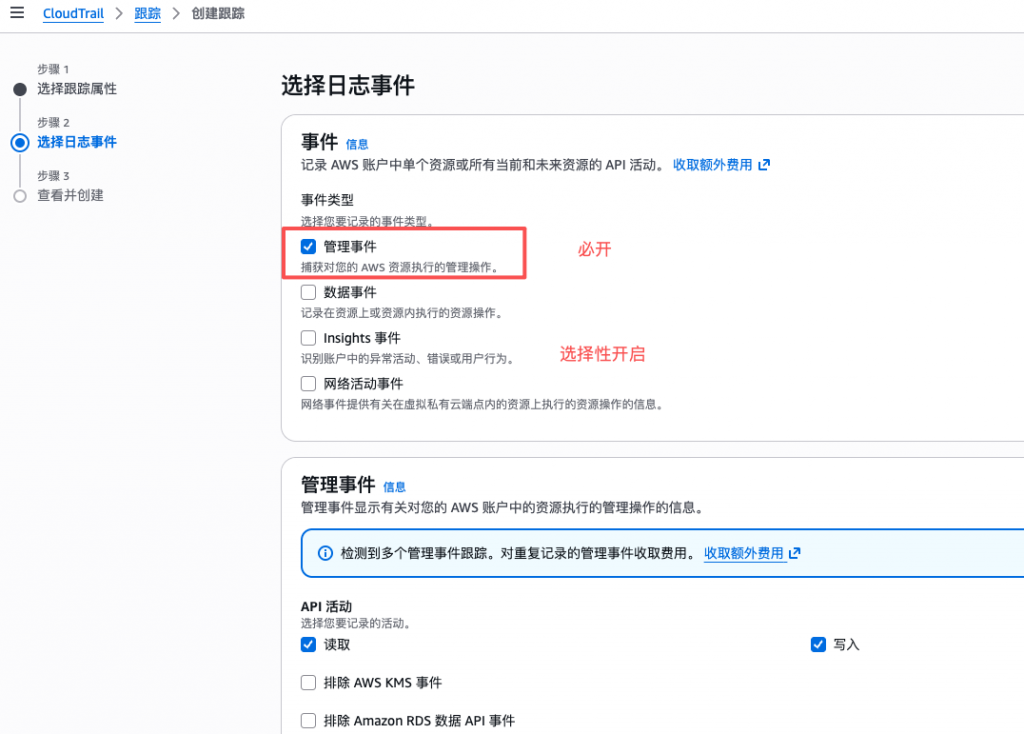
很多环境里,CloudTrail 是“开了,但没完全开”。应急视角下的建议是:
- 管理事件(Management Events):必须开启
- 数据事件(Data Events):只对关键 Bucket开启,否则日志量和成本会迅速失控
开启后,所有事件都可以在 Event History 中查询。在事故调查中,Event History 往往是最先打开的页面。
S3 Server Access Logging 每一次对象访问的记录
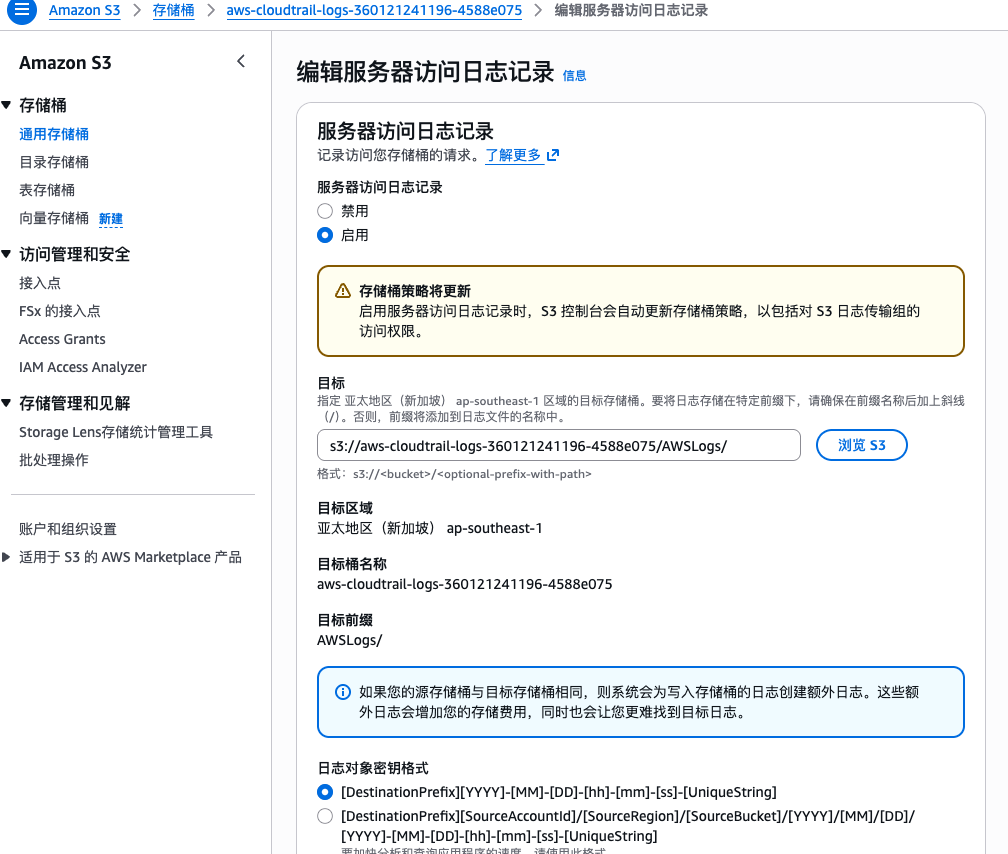
如果说 CloudTrail 更偏“控制面”,那么 S3 Server Access Logging 更偏“数据面”。它记录的是:
- 谁访问了哪个对象
- 使用了什么请求类型(GET / PUT 等)
- 返回状态码
- 访问时间
- User-Agent
- 请求来源
在数据泄露事件中,这类日志经常被用来解决:对象到底有没有被下载?下载了多少次?是哪个 IP、哪个客户端?
注意:S3 默认不会开启访问日志。
也就是说,如果你没有提前打开:事后是无法补救的,很多关键问题只能靠推测。
CloudTrail 和 Server Access Logging的区别
在应急响应中,两者并不是替代关系,而是互补:
- CloudTrail
- 谁调用了什么 API
- 权限、配置、管理操作
- Server Access Logging
- 谁访问了哪些对象
- 数据是否真的被读取
一个解决“有没有人动配置”,一个解决“数据有没有被拿走”。两个日志都是可以单独开启的。
S3存储桶的应急响应思路
发现 S3 未授权访问后如何止损
当确认存在未授权访问迹象时,第一目标不是分析原因,而是阻断损害继续扩大。常见的即时处置动作包括:
- 隔离受影响的 Bucket
- 移除或收紧公开访问权限
- 暂停可疑账号或角色的访问能力
- 阻断异常来源 IP
在这一阶段,宁可影响部分业务,也不要放任风险继续扩散。
优先替换凭证与权限
如果怀疑凭证泄露或被滥用:
- 立即轮换 Access Key
- 修改相关账号密码
- 强制重新授权角色
这是阻断持续访问的最直接方式,也是很多真实事件中最关键的一步。
总结
在云上安全事件中,绝大多数 S3 安全事件并非源于高复杂度攻击,而是由访问控制误配置、凭证管理不当或日志缺失引发。一旦 Bucket 被未经授权访问,如果事前未启用 CloudTrail 和访问日志,就很难判断数据是否被读取、修改或外泄,事件影响范围也无法准确评估。有效的 S3 事件响应,必须以完善的访问控制、持续的监控与日志为基础,在异常发生时能够快速发现、及时止血,并通过完整的取证链路支撑后续复盘与改进。应急响应的成败,往往在事故发生之前就已经决定了。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论