链家-全国二手房源数据爬取思路分析
因为前几天在参加数学建模的比赛,恰好指导老师问我写过哪些爬虫,好像提到了他们之前让学生抓取链家上的房价信息。听老师描述起来好像还有些困难的样子,还有多种反爬措施。于是我就试着爬取了一下链家上二手房的信息,所以就把我在分析抓取数据的过程分享给大家。

在分析网页源码的过程中,我分析的链家成都的二手房信息。之后发现链家上全国各个城市的网站结构基本上都是相同的,所以就改成了多线程爬虫,最终的效果还是非常不错的。
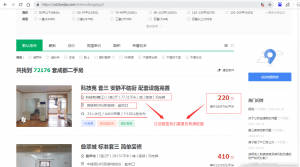
首先观察网页源码,发现所有需要的数据所在的标签源码部分都被压缩过。不像之前分析虎牙斗鱼网页结构时那么清晰。

这时候浏览器的开发者工具就能帮我们高效分析网页结构了,F12后看着所有标签一目了然,分析整个页面结构,数据时方便了不少。
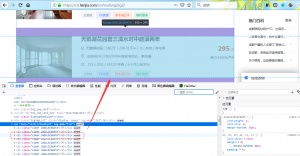
其实在清楚网页结构的情况下,我们的目的就是寻找出对应的标签,这个时候开发者工具简直不要太方便。为了让python代码快速找到标签,我就直接写了一个标签寻找函数,因为该网站的大多数标签都有一个唯一对应的class属性,通过该值就能很快把标签的那部分单独提取出来。实现起来是很快的,只是在分析网页源码标签时花费的时间会多一些。基本上100页成都二手房信息就被爬取下来。
接下来我发现链家在全国还有很多城市都有房源,所以简单观察了一下其他城市的网站结构,除了北京(可能是做过一些修改),用相同代码都是可以爬取下来的。这样就让我萌生了将链家上全国的二手房信息都给抓取下来。
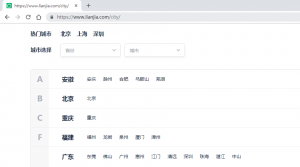
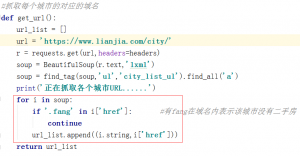
找到链家上有城市的选择页面,里面包含了各个城市的url,直接全部提取出来。

仔细观察后发现,所有url中带有fang的就没有二手房源,所以可以把这些给过滤掉。
然后通过传参的形式将城市名和对应的url交给下一个函数进行页面数据提取。另外让我非常高兴的一点就是链家通过设置子域名来分隔每个城市的,即每个城市的网站都是对应的一台主机!!!这样就省去了抓取页面数量过多而导致被ban掉ip的情况了。把代码扔到服务器里运行时的截图。整体来说效果还是挺好的。
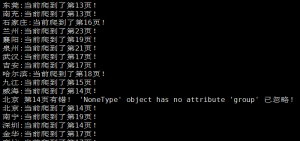
因为链家上面所有的城市数量也不是太多,所以我在考虑多线程爬取的时候想的就是直接一个城市单独创建一个线程,每个线程在爬取一个页面后都sleep一段时间,这个在多线程的情况下对效率的影响显得很小了。保证都不会被ban掉。
下面附上整个爬虫的源码。为了大家学习方便,这次我就没有写到数据库里,换成了txt文本。
import re import time import requests import threading from bs4 import BeautifulSoup #Author:zgao #链家二手房信息抓取 headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'} #根据class属性值寻找标签 def find_tag(soup,tag,content): tag = soup.find_all(tag) for i in tag: try: if i['class'][0] == content: return i except: pass def create_threads(list): #为每个城市创建一个线程 for i in list: city = i[0] city_url = i[1] t = threading.Thread(target=main,args=(city,city_url),name=city) t.start() #抓取每个城市的对应的域名 def get_url(): url_list = [] url = 'https://www.lianjia.com/city/' r = requests.get(url,headers=headers) soup = BeautifulSoup(r.text,'lxml') soup = find_tag(soup,'ul','city_list_ul').find_all('a') print('正在抓取各个城市URL......') for i in soup: if '.fang' in i['href']: #有fang在域名内表示该城市没有二手房 continue url_list.append((i.string,i['href'])) return url_list def main(city,city_url): with open(city+'二手房-链家.txt', 'w',encoding='utf-8') as f: fail_count = 0 for page in range(100): try: page += 1 url = city_url + 'ershoufang/pg' + str(page) + '/' r = requests.get(url, headers=headers,allow_redirects=False) soup = BeautifulSoup(r.text, 'lxml') soup = find_tag(soup, 'div', 'content') soup = find_tag(soup, 'ul', 'sellListContent') for i in soup: try: k = find_tag(i, 'a', '') f.write('标题:' + k.string + '\n') m = find_tag(i, 'div', 'houseInfo') f.write('小区名称:' + m.a.string + '\n') m = re.search('a>.*<', str(m)).group()[4:-1] f.write('简述:' + m + '\n') n = find_tag(i, 'div', 'positionInfo') nm = re.search('an>.*-', str(n)).group()[3:-1] f.write('楼层时间位置:' + nm + n.a.string + '\n') p = find_tag(i, 'div', 'followInfo') p = re.search('an>.*<', str(p)).group()[3:-1] f.write('关注度:' + p + '\n') o = find_tag(i, 'div', 'totalPrice') f.write('总价:' + o.span.string + '万\n') y = find_tag(i, 'div', 'unitPrice') f.write('单价:' + y.span.string + '\n') f.write('链接:' + k['href'] + '\n') f.write('-' * 50 + '\n') except Exception as e: print(city,'第' + str(page) + '页有错!', e,'已忽略!') print(city + ':当前爬到了第' + str(page) + '页!') time.sleep(8) except ConnectionResetError: fail_count += 1 print(city,str(page) ,'链接第',str(fail_count),'次出错,等待重连中,20s....') if fail_count > 3: break time.sleep(20) continue except TypeError: print(city,str(page),'不知道出了什么错,也可能是爬取完成了!') print(city,'信息抓取完成!') if __name__ == '__main__': url = get_url() create_threads(url)
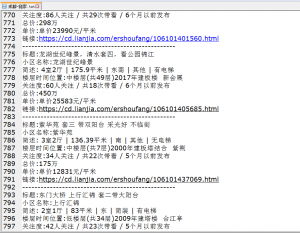
最终的爬取的数据结果如图。每个城市对应一个txt文本。
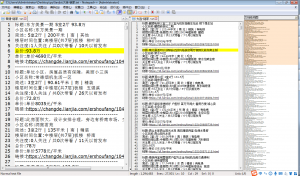
这样链家上全国的二手房信息也就都给爬下来了。可能在我的下一篇文章中会对所有爬取到的的数据进行可视化的图表分析。如果对我上面的代码有不懂的地方,可以和我探讨。或者是有好的优化建议,欢迎指教!
赞赏
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论