浅谈Python中反射机制的应用
一直没具体探究过Python反射机制的应用。恰好最近帮别人写了一个爬虫项目,他们的要求是根据本地图片的文件名,去对应的网站上抓取页面上图片的信息,而他们给的网站有大概有8个,但是每个网站要求抓取的内容都是相同的,都是用xpath来抓取,只是细微不同。我打算通过类来实现,而方法名就是各网站的名称,所以首先就想到了反射机制。
这里我想借助我项目中的这个例子,深入了解一下Python反射机制的应用。
这里先看一下我的代码片段。
from requests_html import HTMLSession
import json
s = HTMLSession()
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
class SiteInfo():
def __init__(self,url):
self.url = url
self.r = s.get(self.url, headers=headers,timeout=5)
def shutterstock(self):
title = self.r.html.xpath('//*[@id="content"]/div[2]/div/div[2]/div[2]/main/div/div[2]/div[1]/h1',first=True).text
a = self.r.html.xpath('//*[@id="content"]/div[2]/div/div[2]/div[2]/main/div/div[2]/div[2]/div/div',first=True)
keywords = ','.join([i.text for i in a.find('div a')])
Categories = self.r.html.xpath('//*[@id="content"]/div[2]/div/div[2]/div[2]/main/div/div[2]/div[2]/p',first=True).text
return (title,keywords,Categories)
def istockphoto(self):
title = self.r.html.xpath('/html/body/div[2]/section/div/main/section[3]/div', first=True).text.replace('...',' ')
keywords = self.r.html.xpath('/html/body/div[2]/section/div/div[4]/section[3]/div/ul',first=True).text
Categories = self.r.html.xpath('/html/body/div[2]/section/div/main/section[5]/div[2]/div[2]/div[5]',first=True).text
return (title, keywords, Categories)
def dreamstime(self):
title = self.r.html.xpath('/html/body/main/div/div[1]/div[1]/div/h1', first=True).text
keywords = self.r.html.xpath('/html/body/main/div/div[1]/div[2]/div[3]/div/ul',first=True).text
Categories = self.r.html.xpath('/html/body/main/div/div[4]',first=True).text
return (title, keywords, Categories)
def rf123(self):
title = self.r.html.xpath('//*[@id="imageTitleText"]', first=True).text
a = self.r.html.xpath('//*[@id="keywordsSpan"]', first=True)
keywords = ','.join([i.text for i in a.find('span a')])
Categories = ''
return (title, keywords, Categories)
def get_info_from_site(website,site):
if site == '123rf':site = 'rf123'
return getattr(website, site)()
website = SiteInfo(url)
title, keywords, Categories = get_info_from_site(website,site)
这里我写了一个SiteInfo的类,其中本来有8个方法,都是相似的,避免太长我就删掉了一部分。
关于抓取的思路,我是这样想的,既然要抓取的内容都是相同的,只是网站不同。按照要求,每个网站都有一个图片的url链接,从图片中获取的id来传入url。所以我定义了这个域名字典,键是网站的名称,值是URL的格式。
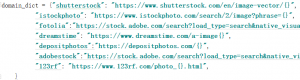
根据键名获取对应的值,但是键名是字符串。而在SiteInfo这个类里面,我所有的方法都是用的网站名称。
也就是说字典的键名是类中的方法名。我们需要直接通过键名来执行SiteInfo类中对应的方法。
通过字符串来调用类中的方法吗这不就是 反射机制 吗?看我的代码实现。
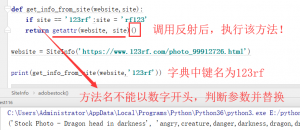
先实例化一个对象,传入url,执行构造函数,请求对应的网站。每个方法对应一个网站的xpath。通过反射键名执行website对象的该方法,实现了我的思路。所有的网站中只有123rf较为特别是数字开头,所以要进行替换。
这里我自己画了一张图来帮助大家理解上面的代码。
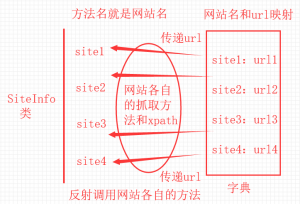
说完了上面的例子,我们深入了解一下反射机制。定义:
利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动。
上面我的代码中只用到了getattr()函数,也是Python自省的核心函数。
在计算机编程中,自省是指这种能力:检查某些事物以确定它是什么、它知道什么以及它能做什么。自省向程序员提供了极大的灵活性和控制力。
和反射相关的函数还有
hasattr(object, name)
判断对象object是否包含名为name的特性(hasattr是通过调用getattr(ojbect, name)是否抛出异常来实现的)
setattr(object, name, value)
这是相对应的getattr()。参数是一个对象,一个字符串和一个任意值。字符串可能会列出一个现有的属性或一个新的属性。这个函数将值赋给属性的。该对象允许它提供。例如,setattr(x,“zgao”,264)相当于x.zgao = 264
delattr(object, name)
与setattr()相关的一组函数。参数是由一个对象(记住python中一切皆是对象)和一个字符串组成的。string参数必须是对象属性名之一。该函数删除该obj的一个由string指定的属性。delattr(x, ‘zgao’)=del x.zgao
介绍完反射的几个函数后,主要还是关于反射一些具体的应用。这里我也参考了网上的一些文章。
1.动态导入模块后通过反射调用方法
这是最典型的一个场景,代码如下:
#Part1
#通过输入字符串导入模块
ImModule = input('请输入要加载的模块名:')
Module = __import__(ImModule)
Module.func()
#Part2
ImModule = input('请输入要加载的模块名:')
Module = __import__(ImModule)
ImFunc = input('请输入要调用的方法')
#getattr仅反射了该方法的内存地址
func = getattr(Module,ImFunc,None)
#调用该方法
func()
当使用import导入Python模块的时候,默认调用的是__import__()函数。直接使用该函数的情况很少见,一般用于动态加载模块。__import__(name, globals, locals, fromlist, level)只有name是必选参数,其他都是可选参数,一般情况下直接使用name参数即可。
在Part1中我们虽然动态导入了模块,但是方法是固定写好的,灵活性不高。Part2中我们通过输入了方法名,利用反射机制动态调用方法,代码灵活性就提高了很多。
2.Web框架中的路由功能(如Django中urls)
通常有这样一个场景:需要根据用户输入url的不同,调用不同的函数,实现不同的操作,也就是一个WEB框架的url路由功能。首先,有一个commons.py文件,它里面有几个函数,分别用于展示不同的页面。这其实就是Web服务的视图文件,用于处理实际的业务逻辑。其次,有一个visit.py文件,作为程序入口,接收用户输入,并根据输入展示相应的页面。
代码如下,两个py文件:
# 当前为commons.py
def login():
print("这是一个登陆页面!")
def logout():
print("这是一个退出页面!")
def home():
print("这是网站主页面!")
# 当前为visit.py
import commons
#例如输入的https://zgao.top/login
def main():
page = input("请输入您想访问页面的url:").strip().split('/')[-1]
if page == "login":
commons.login()
elif page == "logout":
commons.logout()
elif page == "home":
commons.home()
else:
print("404")
if __name__ == '__main__':
main()
这就实现了一个简单的url路由功能,根据不同的url,执行不同的函数,获得不同的页面。但如果commons文件里有成百上千个函数呢(这很常见)?难道在visit模块里写上成百上千个elif?显然这是不可能的!那么怎么办?
仔细观察visit.py中的代码,会发现用户输入的url字符串和相应调用的函数名很相似。如果能用这个字符串直接调用函数就好了!这时候Python的反射机制,就可以帮助我们实现这一想法,其主要就表现在getattr()等几个内置函数上!
现在将前面的visit.py修改一下,代码如下:
# visit.py
import commons
def main():
page = input("请输入您想访问页面的url:").strip().split('/')[-1]
if hasattr(commons,page):
func = getattr(commons,page)
func()
if __name__ == '__main__':
main()
通过getattr()函数,从commons模块里,查找到和inp字符串“外形”相同的函数名,并将其返回,然后赋值给func变量。变量func此时就指向那个函数,func()就可以调用该函数。这个过程就相当于把一个字符串变成一个函数名的过程。这是一个动态访问的过程,一切都不写死,全部根据用户输入来变化。
这里我们还加入了hasattr判断,比如用户输入一个非法的url,由于在commons里没有同名的函数会报错。hasattr可以判断commons中是否具有某个成员,返回True或False。通过hasattr()的判断,可以防止非法输入导致的错误,并将其统一定位到错误页面。
这里我用了两个具体的实例来说明了反射的应用,其实在日常开发中反射的用途还有很多,关键是能够灵活的应用。正如我自己的例子中利用网站名称作为类中方法的名字,这样就能巧妙地利用反射机制提升自己代码的灵活性。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论