用几十行python代码爬取站长之家数万份素材资源
前几天一位朋友在qq上问我,有没有之前我写的爬取站长之家上简历模板的源码,结果找了一下发现之前写的比较碎片化,可用性也不高。所以就把思路重新整理了一下,在重新审计网页源码时发现了更巧妙的思路。将整个爬虫代码优化了很多。做了异常处理后代码也只有几十行,主要是构思十分巧妙。让这次爬虫的代码量少了好几倍,短小精悍。

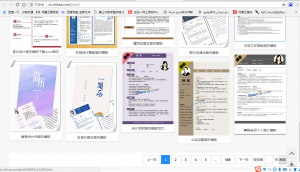
(ps:几千份的简历模板被几十行python代码搞定!)
按照我的风格,话不多说直接上源码!然后再分析整个爬虫的思路。
#coding:utf-8 import re import os import sys import random import requests from bs4 import BeautifulSoup url = 'http://sc.chinaz.com/jianli/free_' headers = {'User-Agent':'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1'} #定义列表存放多个下载源 downloadFrom = ['fjdx','xmdx','gddx','jsdx','fjlt','zjlt', 'xmlt','gdlt','fjyd','sxyd','xmyd','zjyd'] #在当前目录下创建文件夹 try: os.mkdir(r'站长之家个人简历模板') except Exception: pass finally: os.chdir(r'站长之家个人简历模板') for pageNumber in range(2,425): try: page = requests.get(url=url+str(pageNumber)+'.html',headers=headers) page.encoding = 'utf-8' soup = BeautifulSoup(page.text,'lxml') info = soup.find_all('img')[1:] except Exception: print('可能遇到了一些问题,脚本即将退出运行!') print('目前已经爬取到了第'+str(pageNumber)+'页,下次可从这里继续开始!') sys.exit() for tag in info: name = tag['alt'] num = re.search('jianli.*_',tag['src']).group()[:-1] rd = random.choice(downloadFrom) downloadUrl = 'http://'+rd+'.sc.chinaz.com/Files/DownLoad/'+num+'.rar' try: document = requests.get(url =downloadUrl ,headers=headers) filename = name + rd +'.rar' with open(filename,'wb') as f: f.write(document.content) print('文件 '+ filename +' 已下载完成!') except Exception: print('文件 ' + filename + ' 下载失败并忽略!') pass print('目前已经爬取到了第'+str(pageNumber)+'页!')
首先写这个爬虫是因为大一下学期的想给安全公司投简历找实习用的,当时在网上找个人简历的模板。发现网上很多优质的简历模板都是要收费的。找了一些之后发现站长之家上的资源是免费的而且数量还挺多的,虽然和收费的相比还是差了一些,不过也已经够用了。
随便点开一个简历模板,我们会发现站长之家提供了多个下载链接。
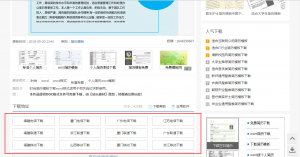
接着去查看网页的源码

发现这些下载链接其实都是站长之家的多个子域名,也就是存放素材资源的服务器,而且他们的命名都是对应的,比如福建电信就是xjdx,广东联通就是gdlt,等等。
为了体现这段代码思路的优越性,我打算先分享我以前的思路,供大家参考对比一下。

这是之前写的代码的一部分,因为代码量大效率又不高,而且过多的对网站资源的扫描容易被ban ip,所以我就不把源码放上来了。这种思路简单来说就是在对网站资源的url进行扫描,判断该资源是否存在,依据是返回的http状态码404或200。
因为站长之家上对素材资源的分类是按照类别,再按年月的日期,接着是文件的编号存放的。例如
http://fjdx.sc.chinaz.com/Files/DownLoad/jianli/201809/jianli8774.rar
http://gddx.sc.chinaz.com/Files/DownLoad/moban/201809/zppt3662.rar
http://zjyd.sc.chinaz.com/Files/DownLoad/webjs1/201403/jiaoben2189.rar
我之前想的就是先对日期进行一次遍历
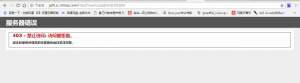
服务器返回了一个403的错误,很多人可能看到这种情况也许就敬而远之了,其实我看到这个状态码其实是非常高兴的。可能是因为我搞渗透的缘故吧,对http状态码十分敏感。403错误说明了该目录存在,但是没有权限查看,也就是说该iis服务器默认关闭了列目录。但重点就是说明了该目录存在呀!!!方便了下一步对文件url的扫描。
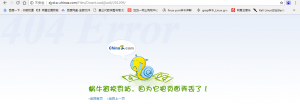
当访问一个不存在的目录时,得到404,该目录不存在,也就不用对该目录的文件进行遍历了。
(闲扯一下:因为平时在做渗透测试的过程中,有的运维人员会故意将非正常的http状态码都以404来返回给用户,这样使得暴露的信息越少,也提高了攻击的门槛)
我定义了一个列表来存放日期,然后对每一个年月份目录下的文件进行遍历。正因为站长之家上的资源的命名都是按照顺序来命令的,这才使得我能用遍历的方式来判断文件资源是否存在。
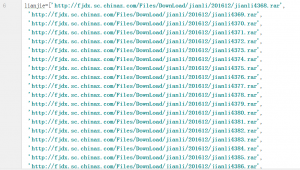
这个是用该思路,抓取到的存在的资源url,并存放到了列表中。
但是这也有局限性,也正是我放弃这个思路的原因,每个资源文件都有一个编号,虽然编号多数情况下是连续的,但出现不连续的时候,会让脚本的遍历失效,而且每遍历一段编号后,又需要更改目录继续遍历。那么问题就很明显了,如何才能让脚本判断出什么时候因为编号不连续造成的还是因为更改目录造成的呢?所以我上学期用这个思路爬取了几百份简历模板后,就把这个思路写的爬虫代码扔一边。
刚好前几天一位朋友可能看了我空间里以前发的说说,想请教一下我关于python爬虫的问题,问我能否分享一下源码。我去看了一下以前的代码,发现这个思路一点也不ok。所以我答应他过几天把这个爬虫代码重写一下,恰好这次的思路十分巧妙,所以也就有了这篇文章。
那么接下来就分析上面的代码,感受好的思路体现出的优越性。之所以这个爬虫的代码量很小,是我在多次审计网页源码后反复观察思考,巧妙地构造出的资源url。这样实际对整个网站网页内容的爬取其实是非常少的,而且频率也非常地低。用一句话来形容就是起到了四两拨千斤的效果吧。那我就以爬取站长之家上的个人简历模板为例,来分析这段代码,当然这个方法对站长之家上的其他素材资源也是有效的。
我们来看一下模板概览每一页的网页源码
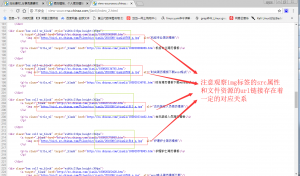
我分别将同一个资源文件的对应的缩略图url和下载链接的url放在下面对比。
http://pic1.sc.chinaz.com/Files/pic/jianli/201809/jianli8767_s.jpg
http://fjyd.sc.chinaz.com/Files/DownLoad/jianli/201809/jianli8767.rar
这应该很明显了吧,这之间存在一个明显的对应关系。
正是因为反复地审计网页源码和仔细观察中发现了有这样的对应关系,才有了这个巧妙的思路。我们可以不用去真正地爬取文件的下载链接,而是去抓取每页中的img标签中的src属性的值。巧妙地构造出文件的下载链接进行爬取。使得代码量减少了很多倍。
同时这个思路实际对网站发起的请求非常少,因为每一页有20个模板,也就是说发起一次http请求能获取到20个简历模板的img的src值。这个用python中beautifulsoup实现起来非常容易。再对src的中我们需要的部分进行正则表达式的匹配提取出来。进行切片操作在拼接到资源下载的url链接中。我相信这些操作都是些基本功了,掌握熟练对我上面的代码理解起来也是十分容易的。所以我就不多做解释了。
另外有一点我想说明,就是在上面的代码中我定义了一个列表来存放了多个下载源。
downloadFrom = [‘fjdx’,’xmdx’,’gddx’,’jsdx’,’fjlt’,’zjlt’, ‘xmlt’,’gdlt’,’fjyd’,’sxyd’,’xmyd’,’zjyd’]
也就是站长之家的多个节点的资源下载服务器,又用了random来保证每次尽可能使用不同服务器来爬取资源,也一定程度上降低了ip被ban掉的概率。因为这个方法的效率非常高,考虑到还是不想被ban ip,所以也就没有写多线程。而且做了异常处理,还是很稳的。即使出错了,还能接着爬。
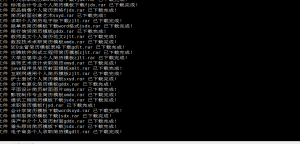
不过发现把这个脚本扔到服务器里面去跑,是真的很舒服(可能是服务器的带宽大而且稳定吧),出去吃顿饭的时间回来差不多就爬完了站长之家上8千多份的个人简历模板。
所以我也把爬取的这些个人简历模板分享出来供大家下载,我放在了我的ftp服务器上
(ps:因为这台服务器是台阿里云学生机,出方向带宽只有1m,下载速度会有点慢,请勿吐槽。)
虽然手里有很多阿里云的肉鸡,但不适合拿来做ftp服务器,所以就将就一下了,哈哈。
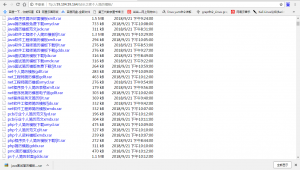
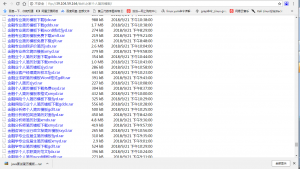
涉及的行业也都挺广的,有需要的小伙伴请自行下载哦。
赞赏
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
5条评论