对成都二手房数据进行可视化分析后,我发现……
我在之前的一篇文章里写过链家上全国所有城市的二手房房价信息抓取的爬虫思路以及代码。之后我便一直在学习数据可视化的内容。因为房价一直都是大家比较关注的话题,二手房价格也不低,新房更是让人望而却步。所以将爬取到的数据拿出来进行可视化分析。

因为上次我不是写到数据库里面的,所以我们要将成都的所有二手房数据的txt文本单独取出来。可直接下载,另存为即可:成都二手房-链家.txt
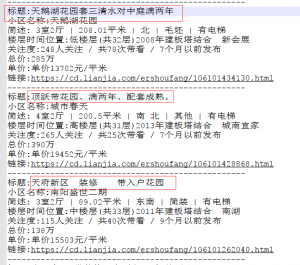
我们首先做一张词云图,就从每个标题中提取出数据。我们需要先把标题给单独提取出来。并且去掉每行的标题两个字。可以简单地写几行代码解决。
with open('chengdu-lianjia.txt','r',encoding='utf-8')as f,open('biaoti.txt','w',encoding='utf-8')as e: for i in f.readlines(): if '标题' in i: e.write(i[3:])
得到单独的标题文件,如图。这里也把提取出来的标题给大家:标题.txt

我们用第三方库wordcloud对来制作词云图,先用jieba进行中文分词。我写了一个get_words的函数来对整个标题文本的词频进行统计再绘图。
这里有一点需要注意的是用wordcloud的generate_from_frequencies方法时,需要传入的是一个字典的数据类型,之前在看csdn上的一位博主写的是列表里嵌套元组,结果一直报错。后来自己去看了该方法的源码后才修正过来的。
import jieba from PIL import Image from collections import Counter from wordcloud import WordCloud def get_words(text): word_dict = {} seg_list = jieba.cut(text) c = Counter() for x in seg_list: if len(x) > 1 and x != '\r\n': c[x] += 1 print('正在进行词频分析.....') for (k, v) in c.most_common(100): word_dict[k] = v return word_dict with open('biaoti.txt', 'r',encoding='utf-8') as f: text = f.read() frequencies=get_words(text) wc = WordCloud(font_path=r'C:\Windows\Fonts\simsun.ttc',width=800,height=400, max_words=200,background_color='white') wc.generate_from_frequencies(frequencies) wc.to_file(r'wordcloud.png') Image.open(r'wordcloud.png','r').show()
还要强调一点,因为wordcloud他没有自带的中文字体,所以没有提供font_path是无法正常显示中文的,大家可以直接在去调用系统自带的中文字体。
通常是在C:\Windows\Fonts\这个目录下。
如果代码运行顺利的话就能得到我们想要的词云图了。
可以看到已经得到文本中的词云,字体越大代表该词出现的频率也越高。也算比较直观地反映了二手房一些明显的特点。是不是感觉很棒呢,我上面的代码只是用到了wordcloud中很少一部分,还要更多的用法大家可以自行去研究。像还可以制作特定的图片形状,背景颜色等等。
接下来我们用pyecharts来对数据进行可视化分析。pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库。用 Echarts 生成的图可视化效果非常棒,pyecharts 是为了与 Python 进行对接,方便在 Python 中直接使用数据生成图。
我特别推荐使用pyecharts,真的非常好用,使用也非常简单。
比如我们将成都的二手房小区的数量进行统计,然后用pyecharts来绘制直方图,代码如下。这里我复用了上面的代码,稍微做了些修改。思路基本上是相同的。
from pyecharts import Bar from collections import Counter def get_words(text): word_list = [] word_dict = {} seg_list = text c = Counter() for x in seg_list: if len(x) > 1 : c[x] += 1 print('正在进行词频分析.....') for (k, v) in c.most_common(100): word_dict[k] = v communities = (k,v) word_list.append(communities) print(word_dict) return word_dict,word_list with open('community.txt','r',encoding='utf-8')as f: text =f.readlines() words_dict,words_list = get_words(text) community_list = words_list[:20] community,num =[],[] for i in range(len(community_list)): community.append(community_list[i][0][:-2]) num.append(community_list[i][1]) bar = Bar('二手房小区数量图','成都') bar.add('小区数量',community,num,is_datazoom_show=True,mark_line=["average"], mark_point=["max", "min"]) bar.render()
滑动下面的进度条浏览可所有数据。
这段代码运行成功后就会在本地生成一个html的文本,图标是通过js渲染的。我用iframe标签将它嵌入到了本页面中。因为小区的数量很多,所以我用可滚动的直方图,只取了数量最多的前二十个小区进行了展示,观察各个小区的数量,非常直观方便。
根据户型这个指标进行分析。代码如下。
from pyecharts import Pie h,num = {},0 with open('chengdu-lianjia.txt','r',encoding='utf-8')as f: for i in f.readlines(): if '简述' in i: huxing = i.split('|')[0][4:-1] if huxing not in h: h[huxing] = 1 else: h[huxing] +=1 for i in list(h.keys()): if h.get(i) < 50: num +=h.get(i) del h[i] h['其他'] = num key,value = list(h.keys()),list(h.values()) pie = Pie('户型比例') pie.add('',key,value,is_label_show=True) pie.render('pie.html')
这里将数量小于50的户型都归为了其他。
我绘制的是圆饼图,各种各样的户型比例一目了然。
根据二手房装修的程度可分为:精装,简装,毛坯和其他这四类。我用空心圆饼图展示。代码和上面的类似,我就不重复了。
感觉大部分二手房的卖家都没有写明这一点。
再对有电梯进行绘图分析。
可见成都大部分均为电梯公寓。二手房中有电梯的也是无电梯的三倍多。
接下开始对二手房面积进行分类。
这个比例还是很合理的。和上面三室两厅的面积也算是差不多的。
接下来可能是大家最关心的问题了,房价!!!
因为每套房子的面积不一样,所以比较总价意义不大,就分析单价。
总共有3000份样本数据,大部分的房价集中分布在1.1-1.7万/平米之间。
3000套二手房单价的平均值是151141.811元,差不多就是1.5w。
这仅仅是二手房的价格,新房的价格我更是不敢直视。所以还是只有分析二手房数据的勇气,哈哈。
考虑到自己以后还要在成都买房,虽然我对房地产这一块了解不多,仅以做数据分析来看,我发现对于一个刚毕业要在成都买房的大学生,又没有父母资助的情况下,
还是洗洗睡吧!
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论