应急响应-统计日志中单个ip访问流量大小
在某次应急排查中,收到网安的自查通告。xxx系统在某一天被某境外组织访问,通信流量xxMb。
分析思路
- 访问ip大概率是境外的
- 通信流量为xxMb
由于该系统全部流量都是经过waf的,可以通过统计当天日志中所有境外ip请求响应包的大小进行比对。
waf日志分析
{"accept":"application/json, text/javascript, */*; q=0.01","appid":1253288859,"body":"","bot_action":"","bot_ai":0,"bot_id":"","bot_label":"","bot_module":"","bot_rule_id":"","bot_rule_name":"","bot_score":0,"bot_stat":0,"bot_ti_tags":"","bot_token":"","bytes_sent":397,"client":"145.224.95.55","connection":"keep-alive","content_type":"-","cookie":"xxxxxxxxx","domain":"xxxxxx.cn","edition":"sparta-waf","encoding":"gzip, deflate","headers":"","host":"xxxxxx","instance":"waf_00000047i","ipinfo_city":"基辅","ipinfo_detail":"Space Exploration Technologies Corporation","ipinfo_dimensionality":39.89489,"ipinfo_isp":"Space Exploration Technologies Corporation","ipinfo_longitude":-2.98831,"ipinfo_nation":"乌克兰","ipinfo_province":"基辅","ipinfo_state":"ES","language":"zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7","method":"GET","msec":1715097564747,"query":"method=initSea330199\u0026requestid=26148343","referer":"http:///spa/workflow/static4mobileform/index.html?_random=1715097543877","request_length":1271,"request_time":0.089,"schema":"http","status":200,"time":"07/May/2024:23:59:24 +0800","timestamp":"2024-05-07T23:59:24+08:00","ua_crawlername":"","ua_fake":0,"ua_goodbot":0,"ua_type":"","upstream":"140.143.159.33:80","upstream_connect_time":0.007,"upstream_response_time":0.082,"upstream_status":200,"url":"/mxxxxxxxxxxxx.jsp","user_agent":"Mozilla/5.0 (Linux; Android 12; ANA-AN00 Build/HUAWEIANA-AN00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/109.0.5414.86 MQQBrowser/6.2 TBS/046805 Mobile Safari/537.36 wxwork/3.0.31000 wxworklocal/3.0.31000 wwlocal/3.0.31000 wxwork/3.0.0 appname/wxworklocal-customized MicroMessenger/7.0.1 appScheme/wxworklocalcustomized Language/zh_CN","uuid":"e46f790def349c22d11f863d86c1da54-633e7ff9d32dcb8bdc2c5ce6fcfb7c89","x_forwarded_for":"-"}
上面是腾讯云waf的原始访问日志,每一行就是一个请求。
其中client是请求的源ip,bytes_sent是响应大小,包含响应头,单位字节,下行带宽。我们需要就这两个字段。
将每个ip的请求单独提取到一个文件
cat waf_access.json| jq -r ".client" | sort -u| xargs -n1 -P 7 sh -c 'grep $1 waf_access.json >$1.txt' _
通过上面这条命令能够实现一次性把所有ip访问请求提取到各自文件中。
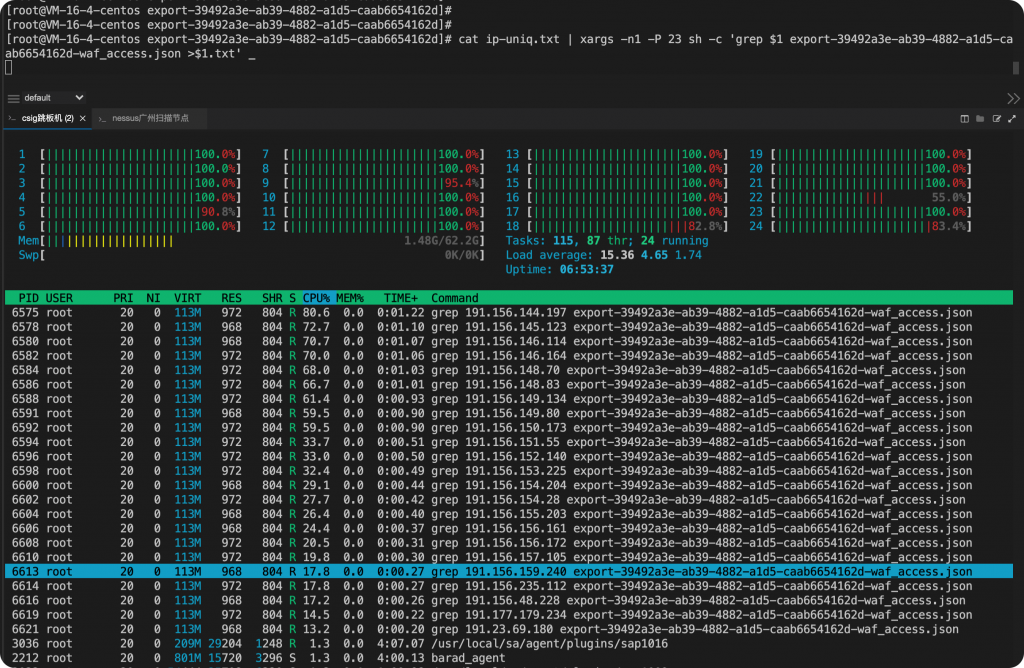
但是这种思路是很不好的,大量重复的匹配非常占用cpu资源和时间。
这样就实现了每个ip的请求都归类到了各自的文件中。
优化命令
上面的命令虽然可以实现,但是非常不优雅,将每个ip重新在文件中匹配了一次。最好的解决方案是只执行一次查找,实现边查边存的效果。
cat waf_access.json | jq -c '. | {client: .client, record: .}' | \
while IFS= read -r line; do
client=$(echo "$line" | jq -r '.client')
record=$(echo "$line" | jq -c '.record')
echo "$record" >> "${client}.txt"
done
- 使用
jq提取每条记录的client字段和整条记录,并将其压缩成单行 JSON 格式。 - 遍历每一行,提取
client字段和对应的记录。 - 将记录追加到对应
client字段值的文件中。
这种方法比多次 grep 要高效得多,因为它只遍历 JSON 文件一次。但是这种方式是一个进程实现的实现,整体速度还是有点慢。
也可以改成多进程的实现。
cat waf_access.json | xargs -n1 -d '\n' -P 20 sh -c 'client=$(echo $1 | jq -r .client) && echo $1 >>"$client".txt ' _
但是每一行都要启动一个新进程来匹配写入文件,效率不高且速度更慢了。
切割文件实现进程并行处理
# Step 1: 拆分 JSON 文件为 20 个小文件
split -n l/20 -d --additional-suffix=.json waf_access.json split_
# 同时并行处理20个文件
ls split_*.json | xargs -n1 -P20 sh -c 'cat $1 | while IFS= read -r line; do client=$(echo "$line" | jq -r '.client');echo "$line" >> "${client}.txt"; done' _
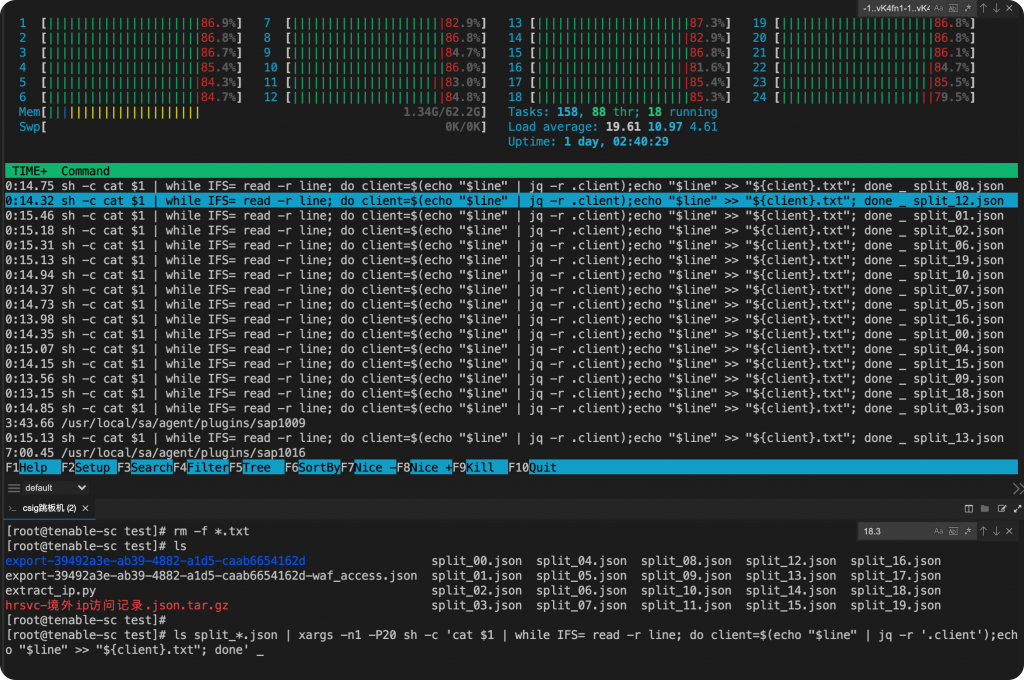
但实际运行还是非常慢,不清楚是不是jq本身的效率就不高?
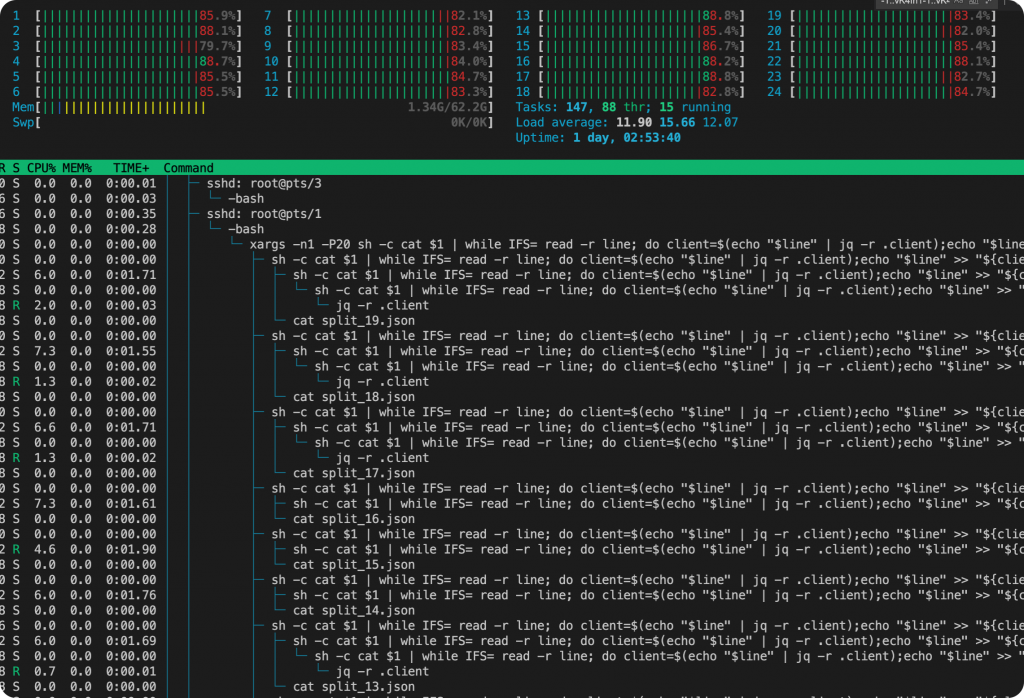
通过分析进程链发现实际上每一个jq都会新产生一个进程来处理,cpu浪费在了上下文的切换上面,效率自然就低了。
python代码实现
import json
from collections import defaultdict
# 打开日志文件
with open('waf_access.json', 'r') as f:
# 读取所有行
lines = f.readlines()
# 使用默认字典来存储每个 IP 的请求
ip_requests = defaultdict(list)
# 处理每一行
for line in lines:
try:
# 解析 JSON 数据
data = json.loads(line)
# 获取 IP 地址
ip = data['client']
# 将该行数据添加到对应 IP 的列表中
ip_requests[ip].append(line)
except json.JSONDecodeError:
# 跳过无法解析的行
continue
# 将每个 IP 的请求写入单独的文件
for ip, requests in ip_requests.items():
with open(f'{ip}.txt', 'w') as f:
f.writelines(requests)
print("完成所有 IP 请求的提取。")
这里是chatGPT给的思路,利用字典的方式巧妙解决多次匹配ip的问题。
经过测试python脚本效率是最高的,基本上单核10几秒就能处理完,而上面的shell命令在24核全部跑满则却需要10分钟的时间。
为什么用collections.defaultdict而不是dict?
使用 collections.defaultdict 而不是普通的 dict 的主要原因是它可以自动为每个新键创建一个默认值。这样就不需要在向字典添加新键时手动检查键是否存在,从而简化代码并避免错误。
在这个具体的例子中,需要为每个 IP 地址存储对应的请求列表。使用 defaultdict,我们可以直接向每个 IP 地址追加请求,而不需要检查该 IP 地址是否已经存在于字典中。
计算每个ip响应包大小总和
ls *.txt | xargs -n1 -P24 -I {} sh -c 'jq -r .bytes_sent {} | awk -v filename="{}" "{ sum += \$1 } END { printf \"%s总计: %.2f MB\n\", filename, sum / (1024 * 1024) }"'
-P 24 是开24个进程同时跑,把机器的cpu拉满。
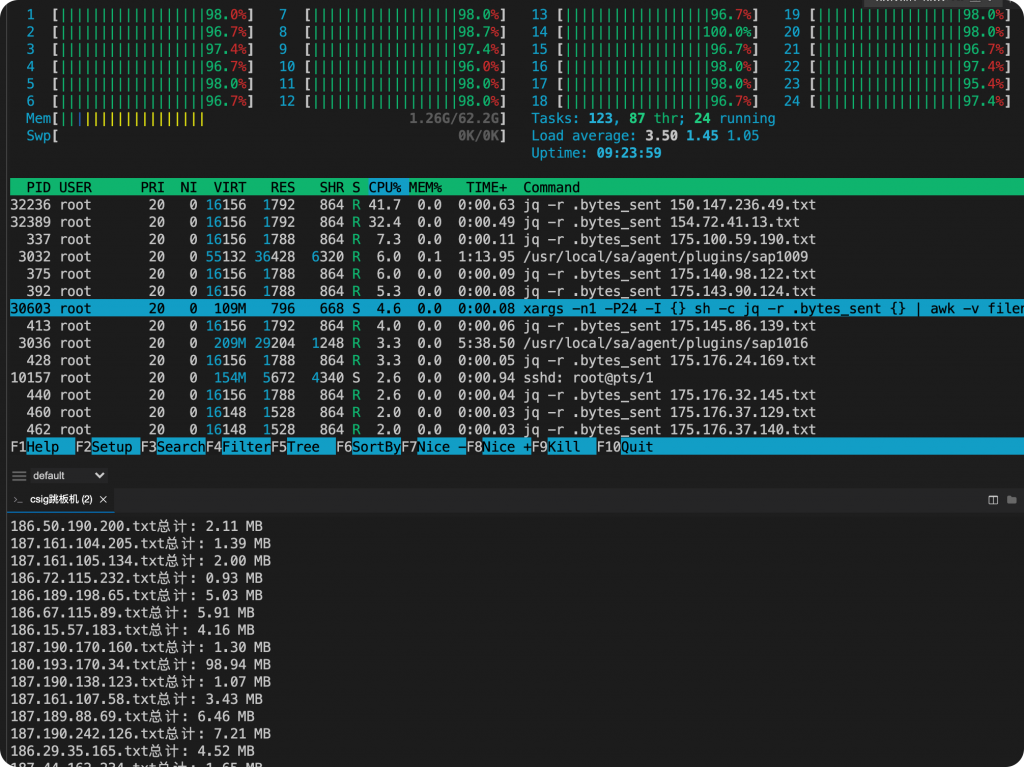
所有ip的访问流量大小都统计出来了,这时再和通告的流量就行比对就能知道是哪个ip的通信流量符合条件了。
同理,Nginx的日志也是可以用这种方法计算的。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
目前为止有一条评论