基于Keras构建卷积神经网络识别正方系统验证码
通过机器学习算法来识别正方系统的验证码是我大二上学期就有的一个想法。不过拖了很久,恰好利用这学期我们学校举办的奔腾杯比赛来做这个事情。因为刚开始接触机器学习,对一些主流的深度学习框架还了解的不深,所以我选择了最简单的Keras,节省了大量的时间成本。这期间参考了大量的文章和别人的模型,才写成本文,由于我目前能力尚且不足,文章难免会有很多疏漏和不足之处,还望各位大佬见谅和指教。

全文的思路是先通过我写的一个验证码标记工具进行人工打码后自动完成二值化后的图片切割作为神经网络的训练样本,最后通过keras构建的神经网络学习后的得到模型来预测新的验证码。正方系统的验证码也就是图中的这个。
可以在新标签页打开该验证码,这样可以看到验证码的url地址为
http://211.83.32.12/CheckCode.aspx
这里我们学校正方系统的ip就不隐藏了,反正只有校园内网才能访问。
下载验证码
因为我们要做验证码识别,所以需要先下载验证码,这个实现很简单。因为训练模型的需要,我是直接写了一个验证码标记工具,每标记一张验证码后直接二值化切割,又重新去get一张,这就需要联网才能标记,但节省很多时间。而不是先抓取一大堆验证码,再统一标记切割,这样会麻烦很多。
其实批量抓取下来的验证码图片就如同这样。
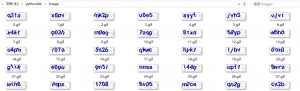
但我在代码中是每次下载一张验证码,这里只展示部分代码
def get_checkcode(i): r = requests.get('http://211.83.32.12/CheckCode.aspx') #这里填入验证码的url picname = str(i) + '.png' with open(picname, 'wb') as f: f.write(r.content)
二值化,去噪,切割验证码
这是整个工具的核心部分,训练的样本数据必须经过这样的处理才能得到好的收敛效果。
这是一张我放大后的验证码图片,每一个小方块就是一个像素点。
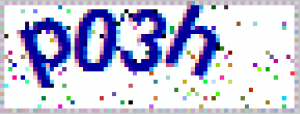
直接查看原图的属性是一张72×27图片。
我们首先要做的是进行二值化操作,就是转换为一张黑白的图片。因为验证码本身是一张P模式的图片,也就是像素点的值是在0到255之间,比操作RGB图片方便了很多。
def process_pic(i): picname = str(i) + '.png' im = Image.open(picname) im = im.point(lambda i: <span style="color: #ff0000;">i == 3</span>, mode='1') im_save =im.save(str(i) + '_after.png') y_min, y_max = 0, 22 split_lines = [5, 17, 29, 41, 53] ims = [im.crop([u, y_min, v, y_max]) for u, v in zip(split_lines[:-1], split_lines[1:])] return ims
这个函数中,我通过point方法来操作每一个像素点,其中写了一个匿名函数来实现,注意观察这里非常巧妙!!!
im = im.point(lambda i: i == 3, mode=’1′)
point()方法通过一个函数或者查询表对图像中的像素点进行处理,其中lambda i遍历整张图片,3是一个阀值,等于3填充为1,不等于3填充为0,mode=’1’的意思是输出模式为整数型,由此实现二值化。
3这个值我试验了很久才找出来,细心观察上面验证码图片的同学会发现验证码中的字符的主体部分都是由深蓝色的点构成的,而这个深蓝色的像素点的值就是3。
为什么说很巧妙呢,因为本身图片中有很多其他颜色作为干扰的噪声,在二值化之后要做的就是去噪。可是我写的这个i==3就是很神奇,在二值化的同时顺便去噪的工作也给我做了,直接看图。

这是另外一张验证码二值化的效果图,虽然还有一个噪点存在,因为这个噪点的像素值也恰好为3,不过效果已经很理想了,而且这个噪点在切割时也会被去掉。当时我在试验的时候,突然萌生的一个想法竟然这么棒,连我自己都被惊讶到了。果然我和写这段生成验证码图片代码的程序员想到一块去了,用同一个像素值的颜色去绘制每个字符的主体部分,再随机添加很多噪声作为干扰。
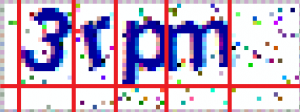
就大概类似于这样的切割,但我这里画的不标准,还请见谅。
[5,17,29,41,53](单张验证码尺寸为72*27),至于字符之间有粘连影响的情况暂时不管,故可以考虑简单切割后识别单个字符。y_min, y_max = 0, 22设定验证码图片中最大的y值和最小的y值。
zip(split_lines[:-1], split_lines[1:]) 运行结果为[(5,17),(17,29),(29,41),(41,53)]
im.crop([u, y_min, v, y_max]) ,crop()函数为用来复制一个图片里的一矩形内容,传入参数为矩形的四条边,这样保证切割处理的图片的长宽都是统一的。所以通过以上的crop()函数实现图片的分割。
以字符6为例,被切割分类后的如图

核心代码其实就是上面这些。
为了标记方便,我用tkinter写了一个简单的图形化界面。由于整体得代码量较大,这里直接附上我写的代码,就不对里面的一些函数单独做解释了,会的看源码就懂了。
import tkinter as tk from tkinter import messagebox import requests from PIL import Image, ImageTk import os def get_cnt(): try: with open('count.txt', 'r') as f: cnt = f.readline() cnt = eval(cnt) return cnt except: with open('count.txt', 'w') as f: f.write('0') return 0 def update_cnt(cnt): with open('count.txt', 'w+') as f: f.write(str(cnt)) def get_checkcode(i): #随便找了个公网能访问的正方系统 r = requests.get('http://jwgl.uoh.edu.cn/CheckCode.aspx') picname = str(i) + '.png' with open(picname, 'wb') as f: f.write(r.content) def process_pic(i): picname = str(i) + '.png' im = Image.open(picname) im = im.point(lambda i: i == 3, mode='1') im_save =im.save(str(i) + '_after.png') y_min, y_max = 0, 22 split_lines = [5, 17, 29, 41, 53] ims = [im.crop([u, y_min, v, y_max]) for u, v in zip(split_lines[:-1], split_lines[1:])] return ims def get_pic_for_display(i): last1 = str(i-1)+'.png' last2 = str(i-1)+'_after.png' if os.path.exists(last1): os.remove(last1) os.remove(last2) picname = str(i) + '.png' im = Image.open(picname) w, h = im.size w_box = 300 h_box = 200 im_resized = resize(w, h, w_box, h_box, im) tk_image = ImageTk.PhotoImage(im_resized) return tk_image def display_after(i): picname = str(i) + '_after.png' im = Image.open(picname) w, h = im.size w_box = 300 h_box = 200 im_resized = resize(w, h, w_box, h_box, im) tk_image = ImageTk.PhotoImage(im_resized) return tk_image def resize(w, h, w_box, h_box, pil_image): f1 = w_box / w f2 = h_box / h factor = min([f1, f2]) width = int(w * factor) height = int(h * factor) return pil_image.resize((width, height), Image.ANTIALIAS) def display_pic(): global im tmp = get_cnt() + 1 get_checkcode(tmp) im = tk.PhotoImage(file=str(tmp) + '.png') im = get_pic_for_display(tmp) picLabel['image'] = im cntLabel['text'] = '第' + str(tmp - 1) + '张验证码' global ims ims = process_pic(tmp) display_after_pic() def display_after_pic(): global im2 tmp = get_cnt() + 1 get_checkcode(tmp) im2 = tk.PhotoImage(file=str(tmp) + '_after.png') im2 = display_after(tmp) picLabel_after['image'] = im2 def save_imgs(): tmp = get_cnt() + 1 code = var.get() for i in range(4): BASE_DIR = os.path.dirname(os.path.realpath(__file__)) path = os.path.join(BASE_DIR, 'split-str', code[i]) if os.path.exists(path): filepath = os.path.join(path, 'count.txt') with open(filepath, 'r') as f: char_cnt = eval(f.readline()) else: os.makedirs(path) filepath = os.path.join(path, 'count.txt') with open(filepath, 'w') as f: f.write('0') char_cnt = 0 charname = os.path.join(path, str(char_cnt + 1) + '.png') ims[i].save(charname) filepath = os.path.join(path, 'count.txt') with open(filepath, 'w+') as f: f.write(str(char_cnt + 1)) update_cnt(tmp) def submit(): save_imgs() display_pic() var.set('') def init(): messagebox.showinfo("初始化窗口", "标记前请确保已连接网络!\n标记后回车即可下一张!") display_pic() def sub_event(event): if event.keysym == 'Return': submit() global im,im2 app = tk.Tk() app.title('正方系统验证码标记工具 --Zgao') app.geometry('500x360+400+220') picLabel = tk.Label(app) picLabel.pack() picLabel_after = tk.Label(app) picLabel_after.pack() var = tk.StringVar() textInput = tk.Entry(app, textvariable=var,width=10) textInput.pack(expand='no', fill='both', padx=200, side='top', pady=10) submitButton = tk.Button(app, text="确定", width='10', command=submit) submitButton.bind_all('<KeyPress>', sub_event) submitButton.pack() cntLabel = tk.Label(app) cntLabel.pack(pady=20) init() app.mainloop()
在打开之前会有一个提示窗口,因为每次输入之后发现点确定都很麻烦,我就给确定按钮绑定了回车键,这样每次标记后直接回车即可。
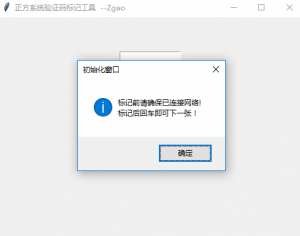
这是确定后进入的程序主界面。
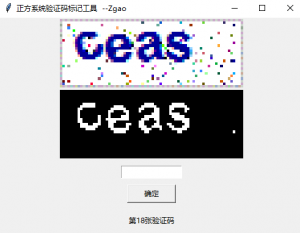
每次标记完成后都会在当前的split-str目录下,生成对应的字符文件夹,被切割后的字符都会放到该字符的文件夹中,在每个目录下又分别有一个count.txt来记录数目。

然后我就把这个工具打包好后发给了我们协会的小伙伴们让大家一起标记,每人标记100张。其实很快就收集到了1000张已标记的验证码。在这里真的感谢群里的各位小伙伴!
另外特别感谢二营长(我室友)的帮忙,因为在收集大家标记的验证码是需要并文件夹,这里二营长帮我用C++做了一些处理,才使得整个过程能顺利进行,附上他的代码。
现在开始用keras训练模型吧!
使用Keras构建神经网络模型非常简单,且在github上可以方便地找到Keras的官方样例,最经典的就是手写字符识别了,即mnist_cnn.py,和这里的目标非常一致,直接拿来用,稍作修改即可。(另外还有简单有趣的mnist_transfer_cnn.py)
Keras 中文文档
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
如果你在以下情况下需要深度学习库,请使用 Keras:
- 允许简单而快速的原型设计(由于用户友好,高度模块化,可扩展性)。
- 同时支持卷积神经网络和循环神经网络,以及两者的组合。
- 在 CPU 和 GPU 上无缝运行。
还有一些关于Keras的安装可以参考网上的一些文章:
DL框架之Keras:Python库之Keras库的简介、安装、相关概念、Keras内模型使用之详细攻略
因为机器学习这方面我还不算特别擅长,所以大家还是多参考网上的文章吧。
到现在已经基本完成了验证码样本数据的收集部分。
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K from PIL import Image import numpy as np import glob import string CHRS = string.ascii_lowercase + string.digits num_classes = 36 # 共要识别36个字符(所有小写字母+数字),即36类 batch_size = 128 epochs = 12 # 输入图片的尺寸 img_rows, img_cols = 12, 22 # 根据keras的后端是TensorFlow还是Theano转换输入形式 if K.image_data_format() == 'channels_first': input_shape = (1, img_rows, img_cols) else: input_shape = (img_rows, img_cols, 1) X, Y = [], [] for f in glob.glob('./split-str/*/*.png')[:]: # 遍历当前目录下所有png后缀的图片 image = Image.open(f) t = 1.0 * np.array(image) t = t.reshape(*input_shape) X.append(t) # 验证码像素列表 s = f.split('\\')[1] # 获取文件名中的验证码字符 Y.append(CHRS.index(s)) # 将字符转换为相应的0-35数值 X = np.stack(X) # Y = np.stack(Y) Y = keras.utils.to_categorical(Y, num_classes) #直接将训练集作为测试集使用 x_train, y_train, x_test, y_test = X, Y, X, Y # 以下模型和mnist-cnn相同 # 两层3x3窗口的卷积(卷积核数为32和64),一层最大池化(MaxPooling2D) # 再Dropout(随机屏蔽部分神经元)并一维化(Flatten)到128个单元的全连接层(Dense),最后Dropout输出到36个单元的全连接层(全部字符为36个) model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) model.save(r'./model.h5')
接下来开始训练模型。
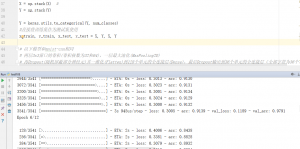
其实收敛速度特别快,大概不到一分钟的时间,acc即达到了0.99。当时看到这个效果时,心里还是特别激动的,为了手动验证一下识别的准确性,我重新写了一个脚本来观察,这里我就没写UI界面了,打开验证码图片的同时在控制台输出识别结果。其实就是将之前的两个脚本中的函数提取出来。
import requests from PIL import Image import keras from keras import backend as K import numpy as np import os import string model_file_path = 'model.h5' img_rows, img_cols = 12, 22 if K.image_data_format() == 'channels_first': input_shape = (1, img_rows, img_cols) else: input_shape = (img_rows, img_cols, 1) CHRS = string.ascii_lowercase + string.digits model = keras.models.load_model(model_file_path) def get_checkcode(i): r = requests.get('http://jwgl.uoh.edu.cn/CheckCode.aspx') picname = str(i) + '.png' with open(picname, 'wb') as f: f.write(r.content) def process_pic(i): picname = str(i) + '.png' im = Image.open(picname) im2 = im.show() im = im.point(lambda i: i == 3, mode='1').resize(x for x in im.size) im_save =im.save(str(i) + '_after.png') y_min, y_max = 0, 22 split_lines = [5, 17, 29, 41, 53] ims = [im.crop([u, y_min, v, y_max]) for u, v in zip(split_lines[:-1], split_lines[1:])] os.remove(picname) return ims def predict_image(images): Y = [] for i in range(4): im = images[i] test_input = np.array(im) test_input = test_input.reshape(1, *input_shape) y_probs = model.predict(test_input) y = CHRS[y_probs[0].argmax(-1)] Y.append(y) return ''.join(Y) for i in range(10): get_checkcode(i) images = process_pic(i) code = predict_image(images) print(code)
我这里识别10张验证码,我这里自行对比发现基本上都是正确的。
这样以后用训练好的模型来直接登录正方系统是真的很棒了。至于模拟登录正方系统的内容我就不再这里细说了。
补充一点:
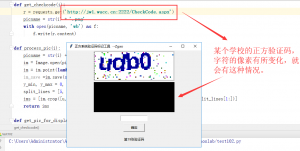
我在网上看了很多其他学校的正方系统,发现这个验证码并不完全相同,可能是版本不同的缘故吧,有的正方验证码的和我们学校的不同。这里的代码中就不能用我那个巧妙的办法了,也就是
im = im.point(lambda i: i == 3, mode=’1′)
其中的i==3可能就需要自己判断,有可能是3左右的某一个数值。因为这本身就是一个取巧的办法!
最后我把这里打包好的工具,训练样本和已经训练好的模型都放到了我网站上,感兴趣的朋友可以直接拿来研究一下。
总结:
为了做这个东西,我还是花了不少的时间来研究,一方面是那个验证码的标记工具,看似简单,实际也花费了不少时间因为在图片切割和二值化那里,特别是为找到那个值进行巧妙的二值化,尝试了很多次。另外在学习卷积神经网络这一块还是付出很多。毕竟自己之前完全没有接触过,期间在b站上看了很多机器学习的视频(为什么是b站?哈哈哈),也参考了很多别人的文章,不断学习才做出这样一个小小的成品。回头看来还是挺欣慰的!收获真的不少。
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论