关于反字体反爬的一种新思路–利用OCR识别
因为前几天一位同学和我讨论如何爬取起点中文网的上小说的数据。其中遇到了一些内容无法抓取,前端显示出来的是正常的,但复制下来却是乱码。我看了网页源码后发现,是用了特殊的字体。所以直接抓取是拿不到数据的。恰好我之前还没遇到过类似的问题,所以就研究学习了一下。自己偶然想出了一个独特的思路从而曲线救国。

随便点开一本小说,我朋友是想抓取每本小说的字数信息,点击量以及推荐量的这些数据。
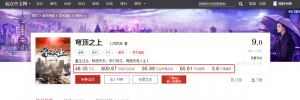
但是从网页源码中是无法看到这些数据的。

发现是用了字体的,所以前端看起来就是正常的。实际上就是字体反爬。
在这里需要先介绍一下@font face。来自百度百科的解释。
}
原文链接:
今天,我终于弄懂了字体反爬是个啥玩意!
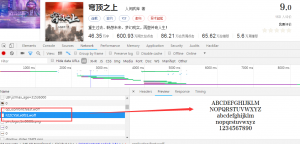
在仔细研究了一番后,要想用他的方法需要自己不断比较,找到新的字体与基本字体之间的映射。虽然效果会很好,但是付出的时间成本就太高了。而且起点中文网中每一篇里面用的字体映射关系是不一样的。
所以我就思考能不能找到更简单的方法呢。
突然灵感来了,既然页面上的看起来是正常的,即人能看懂,那么为什么非得站在代码的角度去解决这个问题呢。我想到了平时我们经常用的图片转文字,不就是用的OCR技术。我为什么不用在这上面呢!
而且python有专门用于OCR识别的库 tesseract 。
所以问题就成了如何将网页上的内容转化成一张图片,再拿给OCR来识别。
我这里就用的selenium来解决的。有各种策略用于定位网页中的元素(locate elements)。
Selenium提供了一些方法来定义一个页面中的元素:
find_element_by_id find_elements_by_name
find_element_by_name find_elements_by_xpath
find_element_by_xpath find_elements_by_link_text
find_element_by_link_text find_elements_by_partial_link_text
find_element_by_partial_link_text find_elements_by_tag_name
find_element_by_tag_name find_elements_by_class_name
find_element_by_class_name find_elements_by_css_selector
find_element_by_css_selector
这里需要注意一下,我在这里踩过的坑。不要用查找的多个元素的方法!这些方法将返回一个列表,无法用来元素截图。因为只差一个s,所以我弄的时候没仔细分辨,结果走了很多弯路。
而我用的就是xpath来定位配合浏览器开发者工具非常方便。而且selenium支持screenshot元素截图。截图的问题也就解决了。
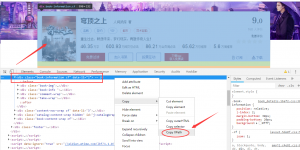
比如说将图上的这个元素给截取下来,在开发者工具中找到对应的标签,然后右键找到copy xpath会将给元素的xpath路径复制下来。代码如下:
from selenium import webdriver
options = webdriver.FirefoxOptions()
options.add_argument('-headless')
browser = webdriver.Firefox(options=options)
browser.get('https://book.qidian.com/info/1013552688')
png = browser.find_element_by_xpath('/html/body/div[2]/div[6]/div[1]')
png.screenshot('image.png')
运行成功就会在当前目录下得到一张image.png的图片,运行期间不会有浏览器窗口弹出,因为设置了无头,如果想看到界面,把那两行代码删了即可。得到的也就是上面元素的截图。
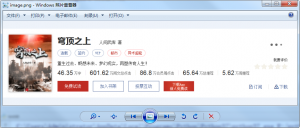
这里只是做一个演示,了解一下原理。我用的是Firefox,其实Chrome都可以,只是Chrome好像在元素截取的时候会出问题,所以就用的Firefox代替的。
触类旁通,要想将上面的数据信息抓取下来,就需要对数字部分分别进行元素截图。然后交给OCR识别即可。代码如下:
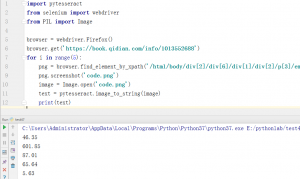
import pytesseract
from selenium import webdriver
from PIL import Image
browser = webdriver.Firefox()
browser.get('https://book.qidian.com/info/1013552688')
for i in range(5):
png = browser.find_element_by_xpath('/html/body/div[2]/div[6]/div[1]/div[2]/p[3]/em[%s]'% str(i+1))
png.screenshot('code.png')
image = Image.open('code.png')
text = pytesseract.image_to_string(image)
print(text)
就会在控制台依次得到每个数据,OCR识别速度相对来说还是比较快的,准确率也非常高。
就这样轻松解决了字体反爬的问题。
而这个网站的爬虫我就不写了,只是分享自己的一种新思路。如果有更简单的方法,欢迎和我交流。
说一下在安装tesseract时可能会遇到的一些问题及解决方法。
python3.5 tesseract-ocr 验证码识别错误解决方案
照着这篇文章中的方法基本都能解决。
另外安装selenium和webdriver时遇到的问题就自行百度或google解决吧!
赞赏
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
发表评论